




.svg)









Incidents already have a lifecycle, but the work inside each stage changes when you introduce LLMs, agent workflows, and automation. The shift is not “AI on dashboards.” The shift is that incident response becomes an evidence-to-decision-to-action system where context is assembled automatically, hypotheses are ranked with differentiating tests, actions are gated by policy, and documentation is produced as a byproduct of doing the work.
AI SRE lifecycle is the practice of applying AI across detection, triage, escalation, communication, remediation, and postmortems so teams reduce time to context, route work to the right owners faster, and execute safer mitigations under explicit governance. This page is a lifecycle overlay. It focuses on what AI changes, what artifacts it should produce, and what guardrails prevent speed from turning into risk. For incident management fundamentals, alerting basics, and full postmortem methodology, we link out to dedicated hubs.
Key Takeaways
- Detection shifts from alert volume to signal precision and clustering.
- Time to context drops when evidence is assembled automatically and hypotheses come with differentiating tests.
- Escalation becomes more accurate when paging is driven by ownership graphs and role recommendations, reducing misroutes and re-pages.
- Communications become more trustworthy when updates are consistent, approval-gated, and comfortable stating explicit unknowns.
- Learning loops tighten when incident outputs convert directly into backlog work, policy improvements, and safer automation allowlists.
The AI SRE Lifecycle Overlay (What Changes, Not What the Stages Are)
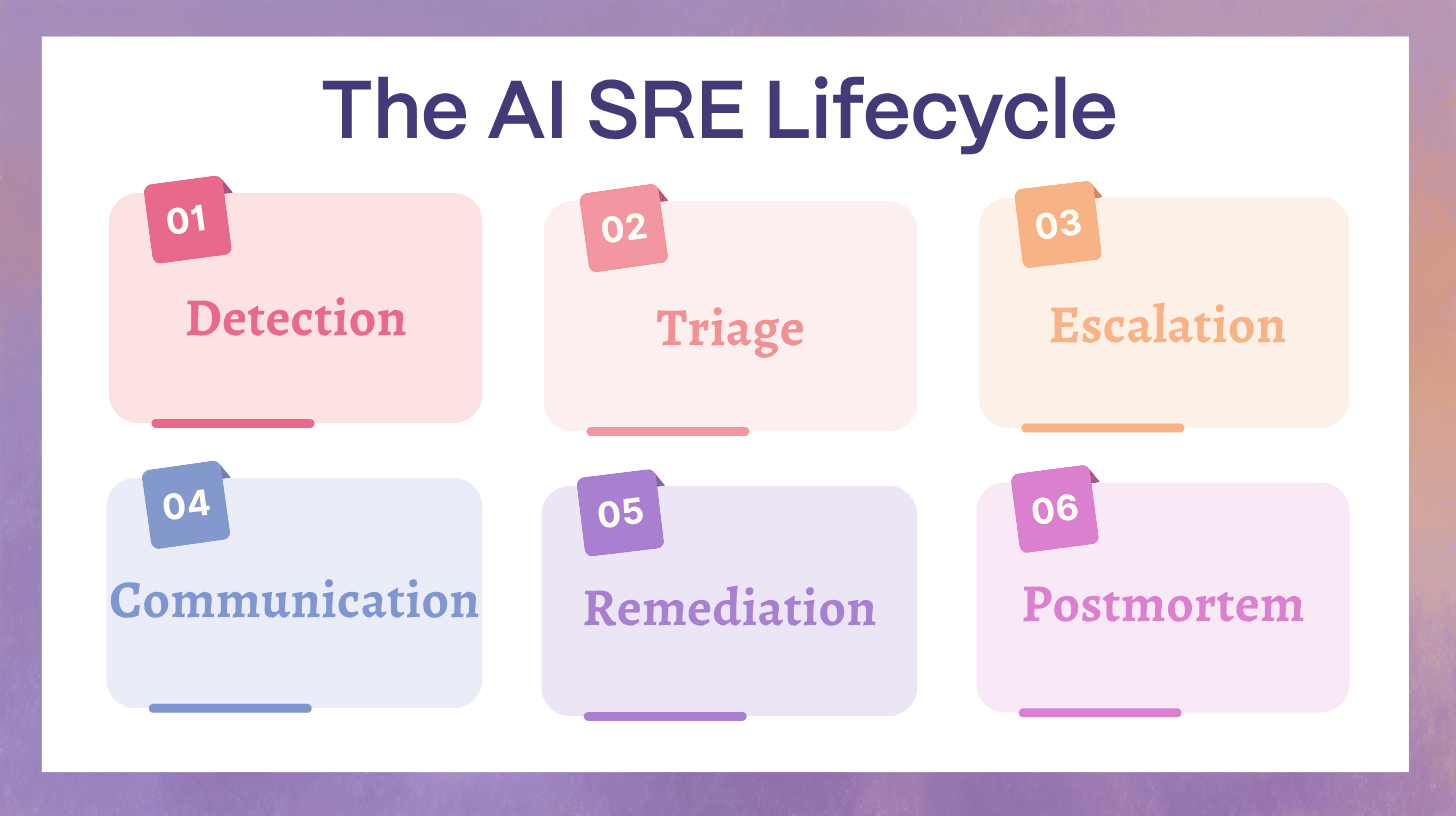
The classic incident lifecycle is familiar: Detection → Triage → Escalation → Communication → Remediation → Postmortem. AI SRE does not rename these stages. It changes the internal mechanics of each stage by adding an overlay of four capabilities:
- Evidence assembly across telemetry, changes, incidents, tickets, and runbooks
- Hypothesis ranking with differentiating tests and disconfirming signals
- Controlled execution where actions are scoped, verified, and reversible
- Documentation by default so timelines and decisions are captured automatically
The practical way to design AI SRE is to define the work products your system must produce at every stage. If you cannot name the artifact, you cannot measure quality, and you cannot put guardrails around it.
The work products AI should create across the lifecycle
- Incident context packet: suspected service, blast radius, recent changes, top signals, impacted SLOs, and likely owners
- Ranked hypotheses: most likely causes plus competing hypotheses, each with differentiating tests
- Action plan: smallest safe actions first, plus guardrails, verification steps, rollback, and stop conditions
- Stakeholder-grade updates: clear summaries, knowns and unknowns, and a timestamped timeline with a decision log
Those artifacts are the “interface” between AI and human responders. They also become the substrate for post-incident learning, auditing, and continuous improvement.
Detection: From Threshold Alerts to Signal Understanding
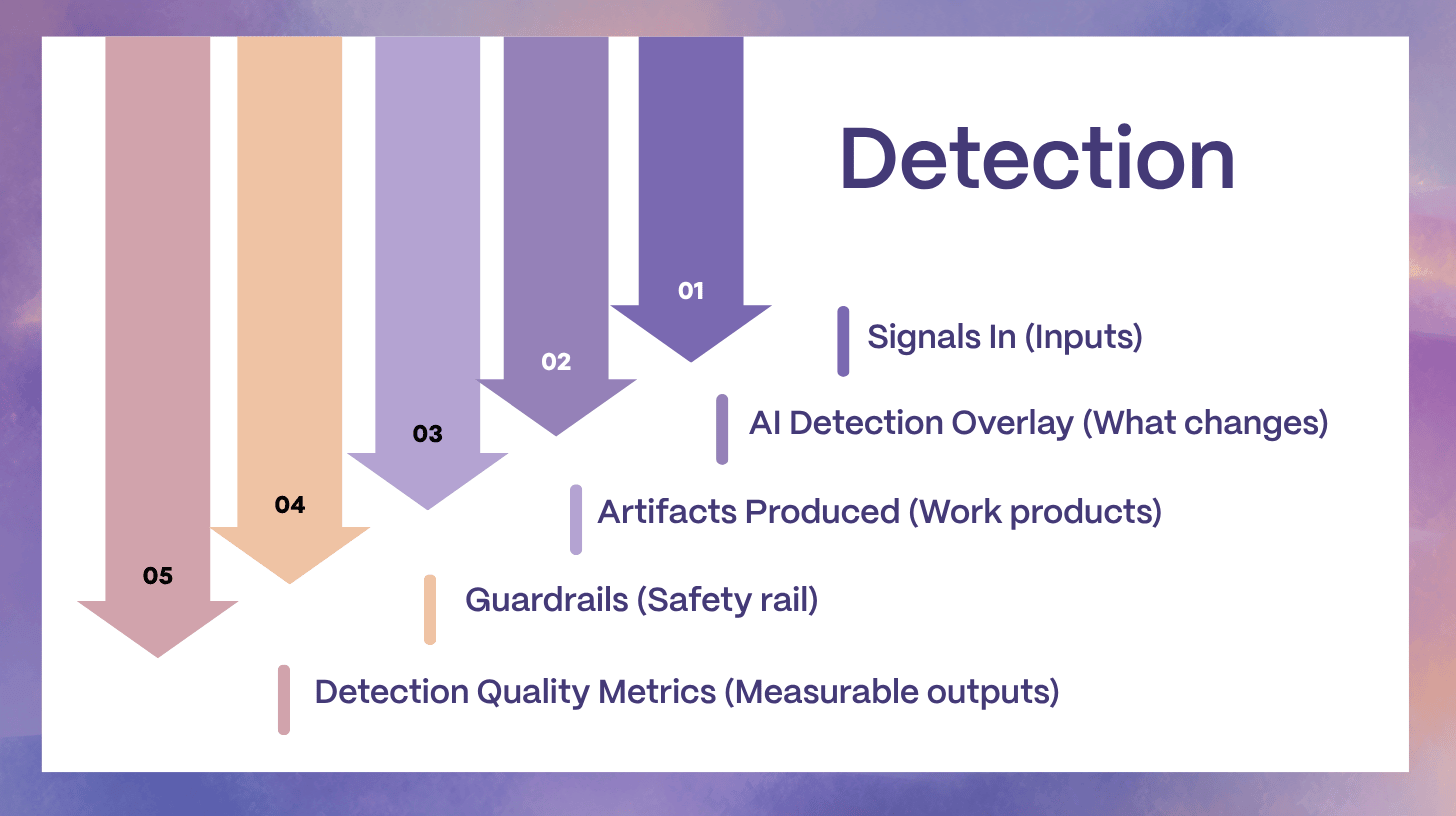
Detection is where most teams lose the first critical minutes. The reason is rarely a lack of alerts. The reason is an excess of poorly grouped signals, missing context, and unclear ownership. In practice, detection quality is about precision, correlation, and early impact estimation, not about generating more notifications.
How Detection Changes with AI SRE
Event deduplication and alert clustering across tools
AI can group related alerts, log spikes, trace errors, and synthetic failures into a single incident candidate. This turns scattered symptoms into a coherent signal cluster. The key design detail is that clustering must be explainable: responders need to see why two alerts are considered part of the same event.
Contextual severity prediction
Severity is not only “how red is the graph.” It is customer impact likelihood, SLO risk, and blast radius probability. AI can estimate severity by combining symptom patterns with service criticality, user journeys, and dependency topology.
Topology-aware anomaly detection
An anomaly without topology becomes guesswork. With service maps, ownership graphs, and dependency edges, AI can propose where the anomaly likely originates and which downstream services are affected.
Detection quality becomes measurable
Treat detection as a quality function: incident candidate precision, duplicate ratio, time to coherent incident candidate, and false page rate. When detection quality improves, on-call load drops and triage accelerates.
Detection Outputs That Enable Faster Response
1) Consolidated incident candidate
A single object that includes correlated alerts and symptoms across systems, including “what changed” signals.
2) Probable affected services and owners
Service catalog mapping is often more valuable than model sophistication. If AI can reliably point to the owning team and the affected boundary, you reduce misroutes and re-pages.
3) Confidence score and “why this matters now”
Confidence should be paired with evidence: top signals, affected endpoints, error budget risk, and recent deployments. This is how you avoid alert fatigue and panic pages.
Guardrails specific to detection
No silent suppression without an audit trail
If AI suppresses or de-prioritizes a notification, it must log the rule, the evidence used, and the time window. Otherwise you create invisible failure modes and erode trust.
Suppression must be bounded
Suppression rules should be tied to evidence, scoped to a service, limited in time, and reversible by design. If a suppression cannot be reversed quickly, it should not exist.
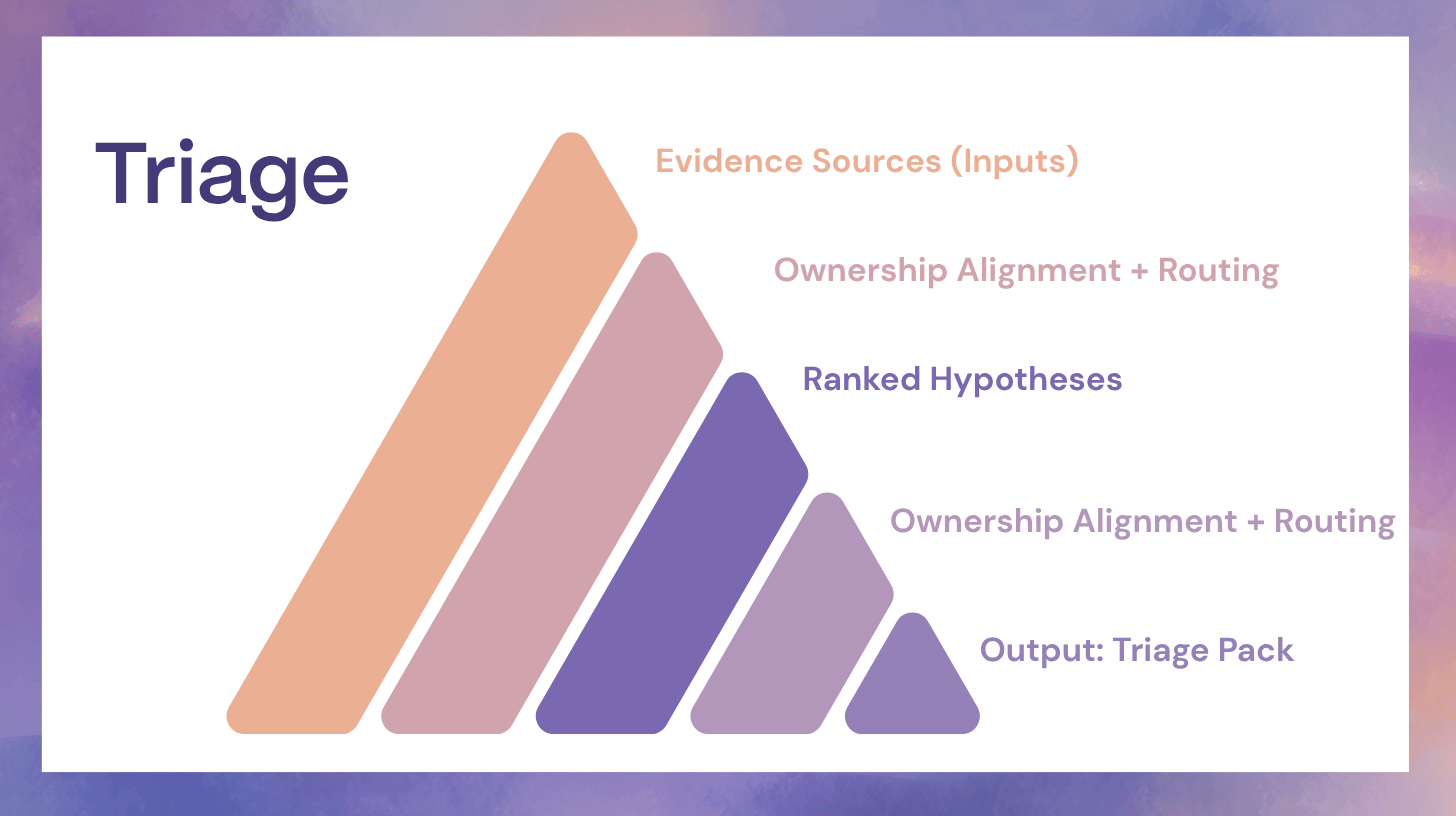
Triage: From Dashboard Hunting to Time to Context
Triage is where incidents either become controlled problem-solving or become chaos. In the classic model, triage is often dashboard hunting: jumping between logs, metrics, traces, deploy timelines, and tickets to reconstruct what is happening. AI changes triage when it is used to compress the “context assembly” phase into minutes.
A practical framing is that “time to context” is the leading indicator for incident outcomes. When teams achieve rapid, accurate context, they reduce wrong turns, reduce misroutes, and resolve faster with fewer risky actions.
How AI Improves Triage in Practice
Automated evidence assembly across sources
AI can pull telemetry summaries, change history, incident history, and runbook references into a single triage pack. This is a retrieval and grounding problem as much as a model problem. If your runbooks are stale or your ownership data is wrong, the AI output will be wrong confidently.
Hypothesis generation with differentiating checks
High-quality triage produces a ranked list of plausible causes plus the shortest tests that discriminate between them. The goal is not to produce a narrative. The goal is to reduce uncertainty quickly.
Ownership alignment and routing
AI can propose the likely owning team and the best first responder based on service boundaries and past incidents. This reduces “ping-pong escalation” and handoff count.
The triage pack
A minimum viable triage pack is not a novel. It is a small, structured set of facts:
- Change snapshot: recent deploys, config changes, feature flag flips, infrastructure changes
- Top anomalies: what is abnormal, where it started, and what it correlates with
- Dependency graph snippet: upstream and downstream dependencies likely involved
- Similar incidents: relevant past incidents with outcomes and mitigations
- Known mitigations: runbook steps or safe mitigations that match the current symptom pattern
If the triage pack is good, responders stop asking “where do I look?” and start asking “which hypothesis is most likely, and what test will prove it?”
Guardrails specific to triage
Evidence-linked claims only
Every claim needs a pointer to the evidence used: a metric summary, a log pattern, a deploy id, a status change, or a runbook step. This is how you prevent confident hallucination from becoming the team’s shared reality.
Show your work for hypotheses
A hypothesis should include: supporting signals, disconfirming signals, and a differentiating check. This forces scientific method behavior under pressure.
Escalation: From Paging People to Paging the Right People
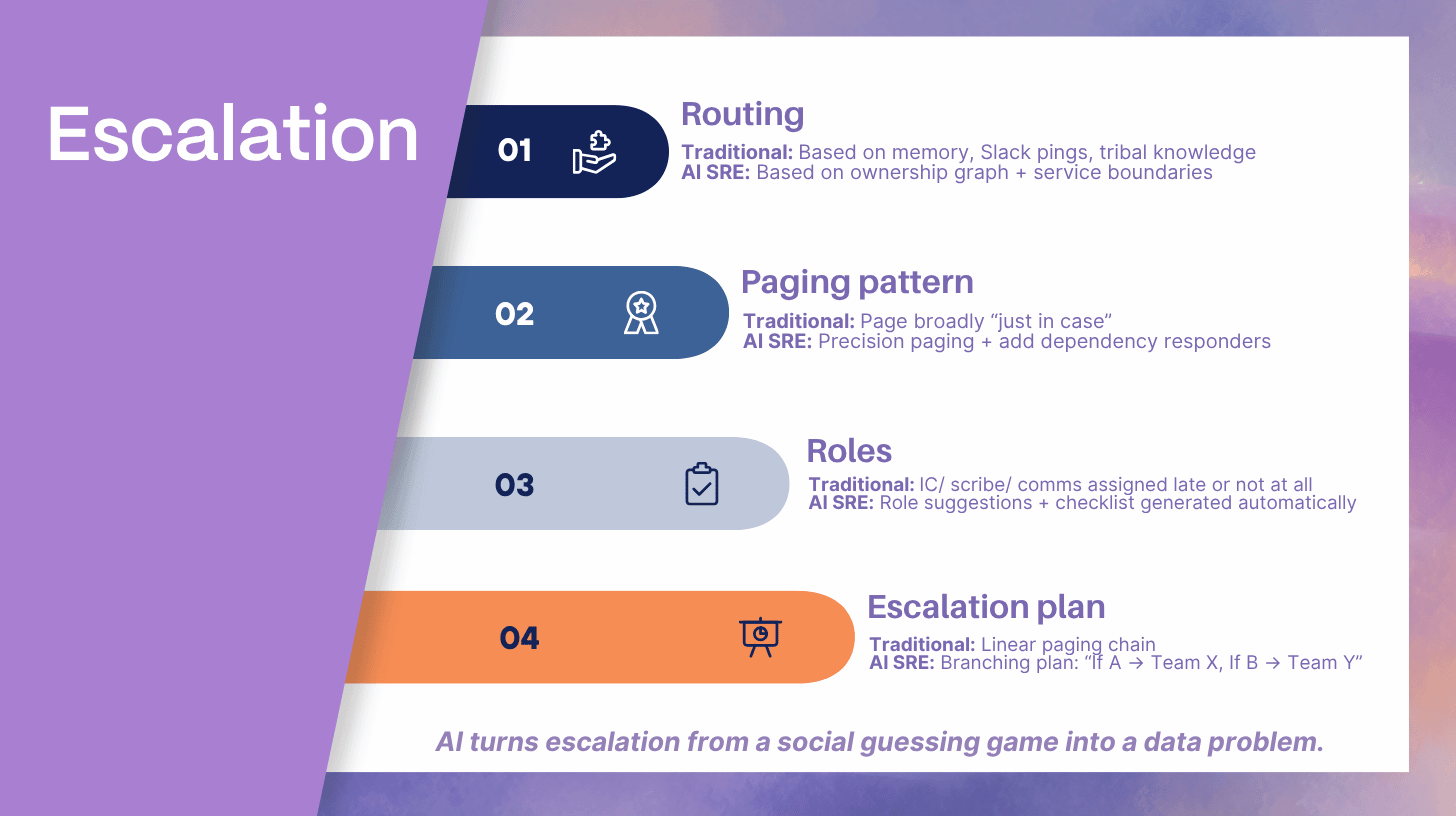
Escalation failures are rarely about paging too late. They are often about paging the wrong team, paging too broadly, or failing to assign roles. AI changes escalation by making routing and role assignment a data problem, not a social guessing game.
How Escalation Changes with AI SRE
Precision paging with ownership graphs
If you maintain a service catalog and ownership boundaries, AI can route incidents to the correct team faster, including secondary responders when a dependency boundary is implicated.
Role assignment suggestions
Many incidents slow down because nobody is acting as incident commander, scribe, or comms lead. AI can suggest roles based on incident type, severity, and team structure, then generate lightweight role checklists.
Escalation path simulation
If hypothesis A is true, you need team X. If hypothesis B is true, you need team Y. AI can propose a branching escalation plan that reduces wasted pages while keeping you ready for likely paths.
Escalation quality signals
- Time to owner: detection to correct owning team acknowledgement
- Misroute rate: pages that land on the wrong team
- Re-page rate: repeated paging due to missed ownership or unclear severity
- Handoff count: number of team transfers before the correct owner takes control
These metrics are often more actionable than MTTR because they reveal structural routing problems and catalog gaps.
Guardrails specific to escalation
Human confirmation for high-severity broadcast pages
For wide-blast notifications, AI should draft and recommend, but humans should confirm. This prevents costly over-escalation.
Rate limits and fallbacks when confidence is low
When AI confidence drops, the system should degrade gracefully: smaller pages, narrower scope, more questions, and an explicit request for human judgment.
Communication: From Manual Updates to Trustworthy, Continuous Narratives
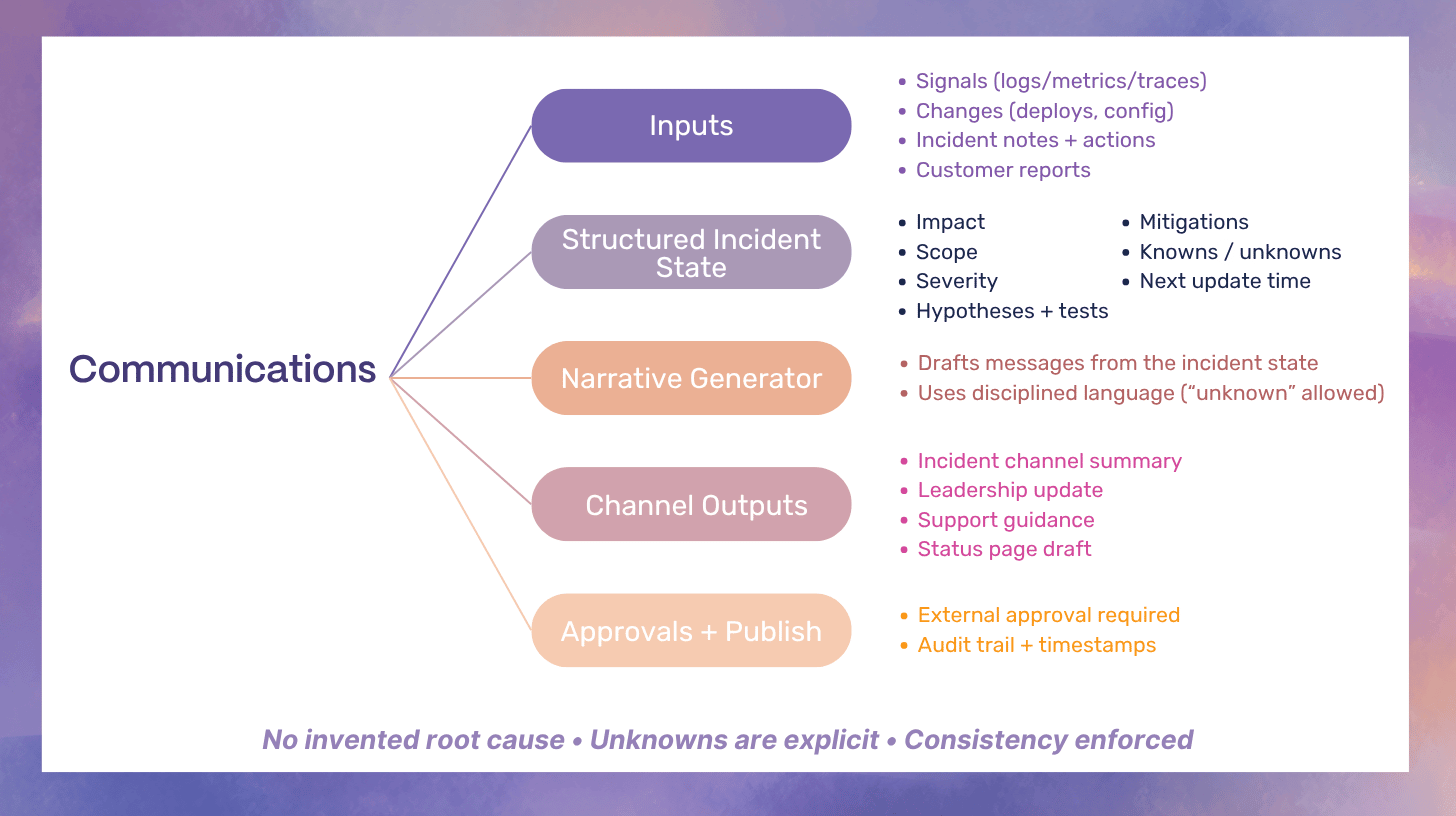
Communication is where trust is won or lost: within engineering, with support, with leadership, and with customers. LLMs can draft updates quickly, but speed is not the goal. Consistency, accuracy, and disciplined unknowns are the goal.
How AI Improves Communications in Practice
Auto-drafted internal and external updates
AI can draft Slack or Teams updates, incident channel summaries, and status page drafts. Done well, this reduces comms toil and keeps responders focused on diagnosis.
Stakeholder-specific summaries
Executives need impact and ETA ranges. Support needs customer-safe language and workaround guidance. Engineers need hypotheses and tests. AI can generate tailored summaries that share the same facts.
Consistency enforcement
One of the biggest comms failure modes is contradictory statements across channels. AI can enforce a single source of truth by generating messages from a structured incident state.
Communication artifacts AI should produce
1) “What we know / what we are testing / next update time”
This structure prevents overpromising and keeps updates predictable.
2) Timestamped incident timeline and decision log
A reliable timeline improves postmortem quality and reduces blame. It also helps leadership understand decision constraints.
3) Customer impact statement templates with safe language
Templates reduce risky phrasing and prevent invented certainty.
Guardrails specific to comms
No invented root cause
Root cause should be treated as a conclusion that requires evidence and verification. Drafts must avoid causal language until verified.
“Unknown” is allowed and encouraged
Teams often fear saying “we do not know.” In reality, explicitly stating unknowns protects trust when done clearly.
Approval workflows for external messaging
External comms should pass through approvals, especially for regulated industries or high-impact incidents.
Remediation: From Runbooks on Wikis to Safer, Controlled Actions
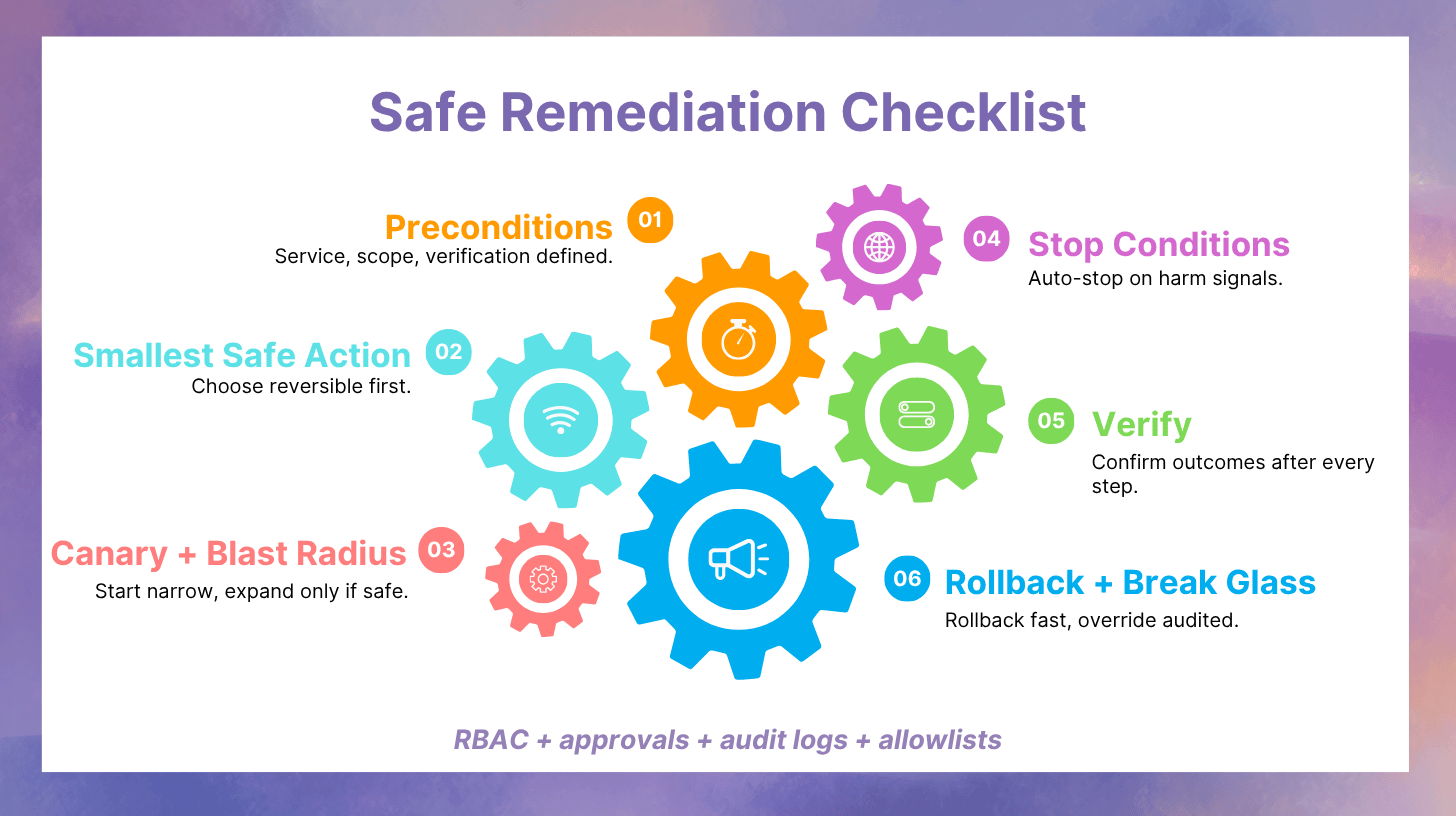
Remediation is where AI can create the most value and the most risk. The right approach is not full autonomy. The right approach is controlled assistance: propose smallest safe actions, verify continuously, and roll back fast.
The business stakes justify this discipline. Many organizations report that downtime can cost hundreds of thousands of dollars per hour, and some industries cite figures in the millions per hour depending on scale and context.
What AI changes in remediation
Suggested mitigations mapped to runbooks and prior outcomes
AI should not invent mitigations. It should retrieve approved runbook steps, correlate them with the current symptom pattern, and present likely success based on historical outcomes.
Smallest safe action first sequencing
Instead of “big restart,” AI should propose reversible steps first: toggling a feature flag, draining a node pool, scaling a known-safe tier, rolling back a single deploy, or reverting a config change.
Change-aware remediation
Remediation should incorporate change context: what deployed, what configuration changed, and what toggles moved. This aligns with modern delivery metrics that focus on recovery from failed changes.
Action safety design (how AI avoids doing harm)
This is where AI SRE becomes architecture, not prompts.
Preconditions
Do not execute unless prerequisites are met: correct service identified, blast radius within limits, and verification signals defined.
Blast radius limits and canary scope
Actions should start in a narrow scope and expand only when verification passes.
Stop conditions
Define what must cause immediate stop: error rate spikes, latency regressions, or any metric that indicates harm.
Verification after every action
Every action needs a “did it work?” check that is defined before the action runs.
Rollback and break-glass controls
Rollback should be immediate and well-rehearsed. Break-glass should be explicit: who can override, when, and how it is audited.
Guardrails specific to remediation
RBAC, approvals, and audit logs
Your control plane matters. Who can run what, under which conditions, and how it is recorded is the difference between safe assistance and dangerous automation.
Allowlist by service, severity, and reversibility
Start with narrow, reversible automations. Expand only after measured success.
Postmortem: From Retelling Events to Improving the System Faster
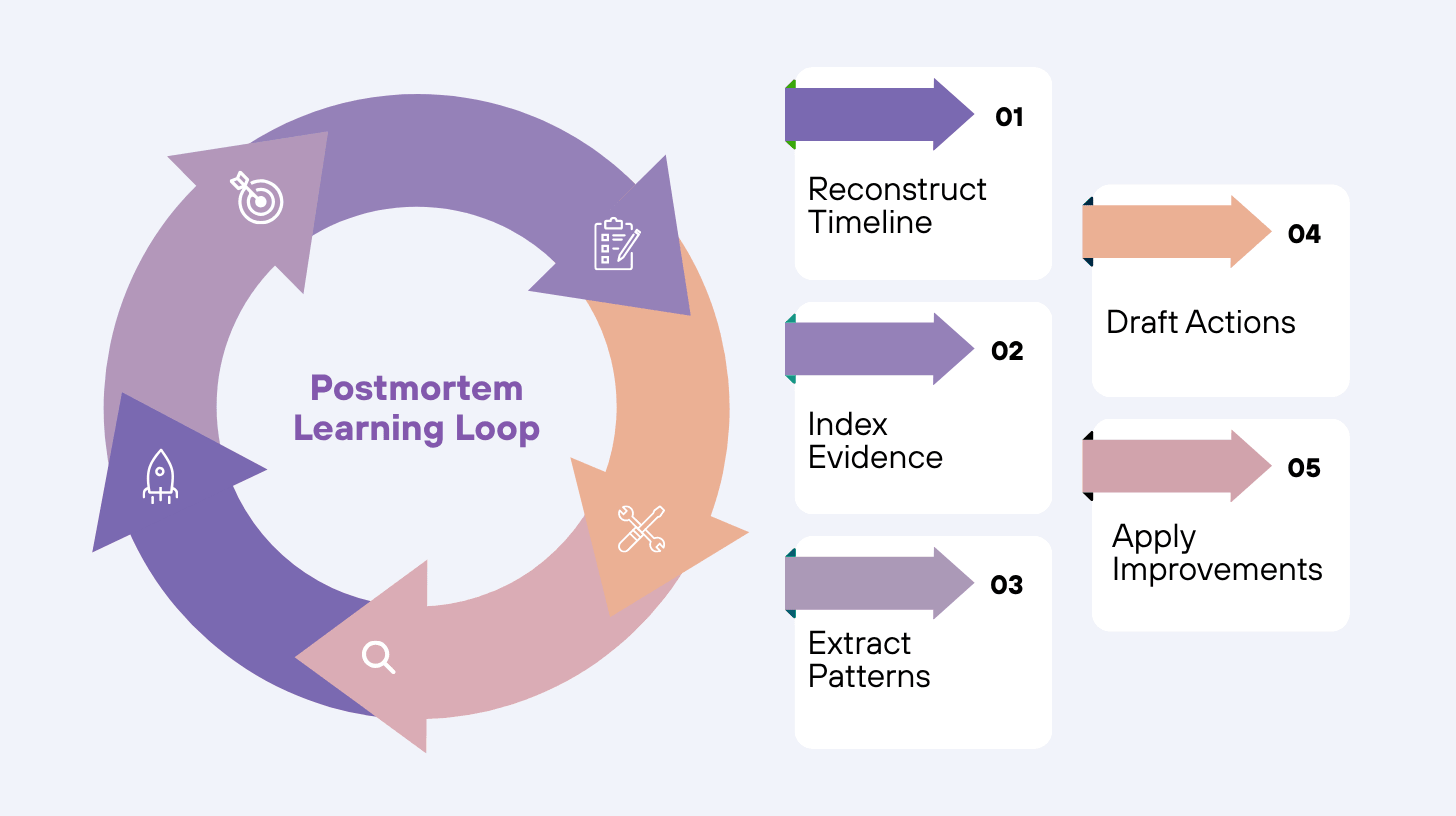
Postmortems often fail because teams spend too much time reconstructing the timeline and too little time improving the system. AI changes postmortems by making reconstruction and indexing cheaper, so learning loops tighten.
Google’s SRE guidance treats operational toil as something to be constrained so teams can spend meaningful time on engineering improvements. Within Google SRE, a commonly cited goal is keeping toil below 50% of time so at least half remains for engineering work that reduces future toil or improves services. That philosophy applies directly to postmortems: the goal is durable engineering change, not storytelling.
What AI changes in postmortem work
Timeline reconstruction and evidence indexing
AI can compile chat logs, incident tool events, deploy timelines, alert streams, and dashboards into a coherent timeline with references.
Contributing factor extraction across incidents
When you index multiple incidents, AI can identify recurring patterns: fragile dependencies, noisy monitors, manual steps that always fail, or repeated misroutes.
Recommendation drafting tied to owners and due dates
Recommendations without owners do not ship. AI can propose action items with clear owners, measurable outcomes, and due dates, then integrate with tracking systems.
The learning loop that matters
The learning loop is not “write a postmortem.” The learning loop is:
- Convert incident artifacts into backlog items
- Improve detection rules and correlation logic
- Update runbooks and approval policies
- Expand safe automations only after proven outcomes
Guardrails specific to postmortems
No blame language
Blameless language increases accuracy because people share real constraints and mistakes.
Evidence-backed conclusions and clear unknowns
If you cannot prove causality, keep it as a hypothesis and state what evidence would confirm it.
The Four System Capabilities That Make AI Useful Across the Lifecycle
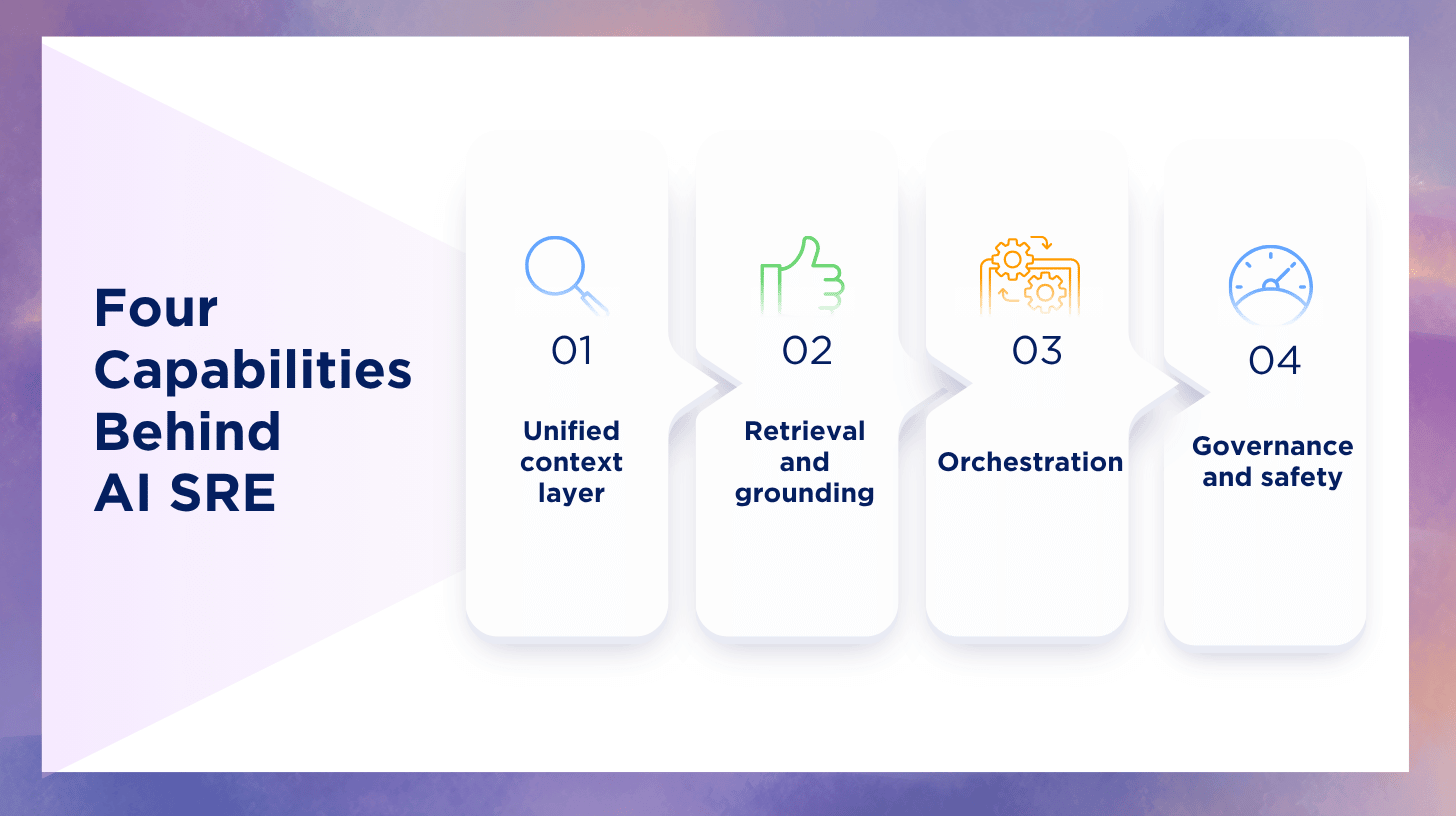
If AI outputs are inconsistent, hallucinated, or unsafe, it is usually not a model failure. It is a systems capability gap. AI SRE depends on four capabilities that show up in every stage.
1) Unified context layer
This includes service catalog, ownership, dependency topology, SLOs, and change history. Without it, you cannot route, scope blast radius, or prioritize impact.
2) Retrieval and grounding
This includes runbooks, tickets, past incidents, architectural docs, known failure modes, and operational policies. Retrieval must be permission-aware so sensitive data is not exposed broadly.
3) Orchestration
Workflows, tasks, integrations, and action execution systems matter. AI should not be a chat window. It should be a workflow engine that creates tasks, runs checks, requests approvals, and records outcomes.
4) Governance and safety
This is RBAC, approvals, audit logs, policy, and confidence thresholds. Governance is not red tape. It is how you get speed without risk.
Guardrails by Design: How to Prevent Hallucinations from Becoming Incidents
Hallucinations are not only a text problem. In operations, a hallucination can become an action, a page, or a customer statement. That is why guardrails must be designed as product requirements.
Grounding rules and citations
Require that every claim ties to evidence: a deploy id, a metric aggregate, a trace exemplar, or a ticket. If evidence is missing, the output must say “unknown.”
Confidence thresholds
Confidence should determine what the system is allowed to do. Low confidence should trigger questions and narrower proposals, not broad actions.
Human-in-the-loop gates by severity
The higher the severity, the stronger the gates: comms approvals, action approvals, and escalation confirmations.
Read-only first rollout
Start with read-only copilots that assemble context and draft hypotheses. Only after measured success should you allow assisted actions, and only for reversible steps.
This design approach aligns with how modern engineering orgs treat reliability and delivery as measurable systems, including metrics evolution that clarifies recovery measurement in real-world contexts.
Metrics That Prove AI SRE Is Working (Beyond MTTR)
MTTR matters, but it is a trailing indicator. AI SRE is easiest to validate with metrics that reflect early-incident quality and workflow efficiency.
Context and routing metrics
- Time to context: time from detection to a validated context packet that includes likely owner, recent changes, and top signals
- Misroute rate: percentage of incidents that page the wrong team first
- Handoff count: how many transfers occur before correct ownership stabilizes
- Re-page rate: repeated pages due to unclear ownership or severity
Signal quality metrics
- Alert dedupe ratio: how much raw alert volume is collapsed into coherent candidates
- Incident candidate precision: how many candidates become real incidents vs false positives
- Detection latency to coherent candidate: time from first symptom to consolidated candidate
Action safety metrics
- Action success rate: percentage of assisted actions that improve verification signals
- Rollback rate and time: how often you roll back, and how fast you recover from a bad action
- Policy violation rate: attempted actions blocked by guardrails
Communications metrics
- Comms latency: time from incident start to first stakeholder update
- Consistency: alignment of facts across internal and external channels
- Update reliability: adherence to promised next update times
Toil and load metrics
- Toil reduction: hours saved per incident across comms, evidence assembly, and documentation
- On-call load balance: distribution of pages and incident hours across teams and individuals
90-Day Adoption Map (Lifecycle-first rollout)
Days 0 to 30: detection + triage copilots (read-only)
- Build the unified context layer: service catalog, ownership, dependency map, change history
- Ship a triage pack that assembles evidence and proposes hypotheses with differentiating tests
- Add detection correlation that produces consolidated incident candidates
Days 31 to 60: comms automation + escalation routing improvements
- Draft internal updates automatically from incident state
- Create stakeholder-specific summaries and enforce fact consistency
- Improve escalation routing using ownership graphs, plus role suggestions
Days 61 to 90: assisted remediation for reversible actions
- Start with allowlisted, reversible actions tied to runbooks
- Add verification and rollback requirements for every action
- Expand scope only after measured action success and low policy violations
FAQs
What is time to context?
Time to context is the time it takes to move from “we have alerts” to “we know what service is impacted, what likely changed, what signals matter, and who owns the response.” It is the fastest way to predict whether triage will be efficient or chaotic.
Can AI auto-resolve incidents safely?
Yes, but only for narrow, reversible failure modes under strict guardrails: RBAC, approvals, allowlists, verification after every action, and automatic rollback. Most teams start with read-only copilots, then assisted actions, then limited autonomy for well-understood scenarios.
What data does AI need to be useful?
AI needs reliable ownership data, service boundaries, dependency topology, change history, and high-quality telemetry. It also needs grounded operational knowledge: runbooks, incident history, and policies. If your service catalog is stale, your AI routing will be wrong.
How do you keep AI from making things up?
You require evidence-linked claims, enforce “unknown” when evidence is missing, apply confidence thresholds, and gate actions and external comms with approvals. You also log every suppression, recommendation, and action for auditing.
Where should we start: detection, triage, or comms?
Most teams start with triage because time to context is the biggest early-incident lever. If you already have strong triage but weak stakeholder discipline, start with comms drafts and timeline automation. If your paging is chaotic, start with detection correlation and ownership mapping.
How do we measure success in the first 30 days?
Measure time to context, misroute rate, alert dedupe ratio, and comms latency. These improve before MTTR changes. Also measure toil saved per incident because it reflects immediate operational value.
Putting the AI SRE Lifecycle Into Practice
AI changes the incident lifecycle when it upgrades the work, not the labels: faster evidence assembly, clearer ownership routing, more disciplined communication, and safer remediation under governance. The teams that win are not the ones with the most automation. They are the ones that make context and control repeatable, so every incident produces reliable artifacts, measurable quality signals, and improvements that stick.
At Rootly, we see the biggest gains when teams standardise a few lifecycle artifacts across every incident: a context packet, ranked hypotheses with differentiating checks, approval-gated updates, and a verified action plan with rollback. If you want to see what this looks like in a live incident workflow, book a demo with us to walk through an AI-ready incident lifecycle from detection through postmortem.