




.svg)









AI SRE architecture is the design of a reliability system where AI assembles incident evidence, forms testable hypotheses, and recommends or executes controlled actions across your stack while humans retain authority. It is not “AI on dashboards.” It is an evidence to decision to action workflow, built with a control plane and safety guardrails from day one.
In practice, this architecture connects telemetry (logs, metrics, traces) with change context (deploys, configs, feature flags) and operational knowledge (runbooks, postmortems, service ownership) so teams can reach a credible diagnosis faster and take safer next steps. The goal is not automation for its own sake, but faster time-to-context, reduced toil, and guardrailed execution that scales incident response without sacrificing accountability.
Key Takeaways
- AI SRE architecture is a workflow layer that turns telemetry plus change and incident context into verified decisions and safer actions.
- The stack needs two planes beyond “AI”: a control plane (RBAC, approvals, audit) and a safety plane (verification, rollback, stop conditions).
- High-quality topology and ownership data often matter more than model choice for reducing time to context.
- Start with read-only copilot patterns, then progress to assisted actions, then limited autonomy for narrow, reversible failure modes.
- The best architectures bind every claim to evidence and force verification before any risky action runs.
The AI SRE Stack at a Glance
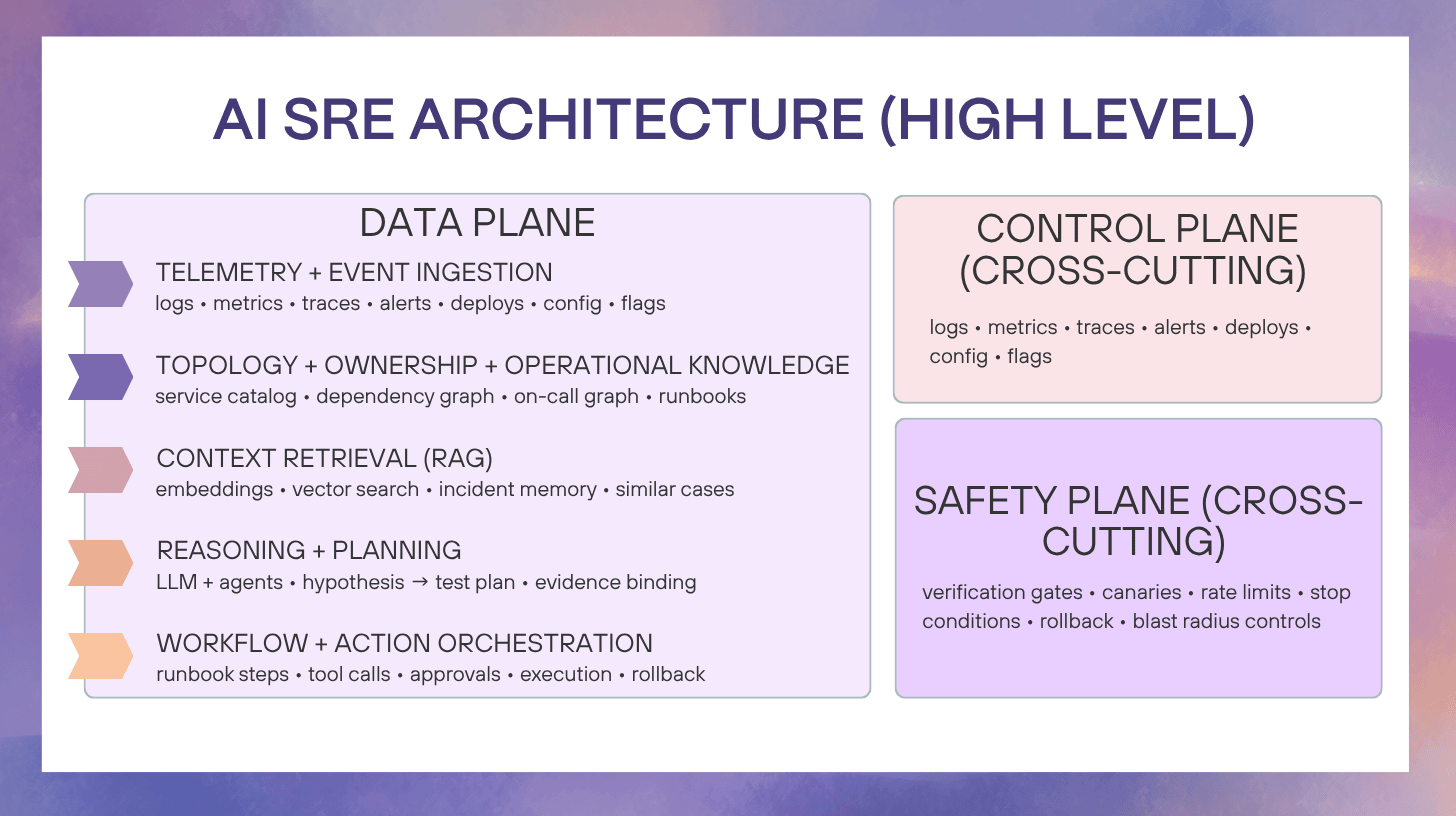
A practical AI SRE architecture is easiest to reason about as five layers plus two cross-cutting planes.
The five layers
- Telemetry and event ingestion
- Topology, ownership, and operational knowledge
- Context retrieval (embeddings + Retrieval-Augmented Generation (RAG))
- Reasoning and planning (LLM + agent loop)
- Orchestration and controlled execution (workflow engine + tools)
The two planes that prevent disasters
- Control plane: identity, RBAC, approvals, audit trails, policy-as-code
- Safety plane: verification gates, canaries, rollback automation, blast-radius controls, stop conditions
If your “AI SRE” design does not clearly show these planes, it is usually just chat plus dashboards.
Layer 1: Telemetry, Events, and Ingestion
What “good” looks like
Your AI layer can only move as fast as your data plane. “Good” in 2025 looks like:
- Unified telemetry across logs, metrics, and traces (OpenTelemetry is the common backbone in many modern stacks).
- Event streams for deploys, config changes, feature flags, autoscaling, paging, and incident state transitions.
- High-cardinality discipline: service, environment, region, tenant, build SHA, and request identifiers are consistently tagged.
Why normalization is architectural, not cosmetic
AI SRE depends on correlation primitives:
- trace IDs that bridge logs to traces
- deploy IDs that bridge incidents to changes
- stable service identifiers that bridge ownership to impact
If you have three names for the same service, the model will produce three stories. Your architecture’s first job is to make “what changed?” and “what is impacted?” computable in minutes, not tribal.
Layer 2: Topology, Ownership, and Operational Knowledge
This layer is where most “AI incident copilots” quietly fail, because they treat topology like optional metadata.
Topology that reflects reality
Your system needs a living map:
- service catalog (or service registry)
- dependency graph (upstream and downstream)
- critical paths (user journeys, revenue paths, clinical paths)
- ownership mapping (team, escalation policy, SMEs)
Ownership is a first-class data product
During an incident, the fastest improvement is often not “better anomaly detection.” It is routing the right humans and context immediately:
- who owns checkout latency in prod us-east
- who owns the feature flag system
- which team is on call right now
Operational knowledge that is retrievable
Runbooks and postmortems must be:
- searchable
- current (versioned, with owners)
- structured enough to retrieve (sections like symptoms, checks, mitigations, rollback steps)
If you do nothing else, build knowledge hygiene. It is the highest leverage “model improvement” you can buy.
Layer 3: Context Retrieval That Actually Helps Incidents (Embeddings + RAG)
This is where AI SRE becomes more than a chatbot. Retrieval is what turns the model from “plausible” to “useful.”
What goes into retrieval
High-value sources:
- incident timelines and decisions
- validated mitigations and verification steps
- known failure modes (symptom → cause patterns)
- change records (deploys, config diffs, flag flips)
- runbooks and escalation notes
High-risk sources (require tighter controls):
- raw secrets or credentials
- unrestricted internal docs with sensitive data
- untrusted inputs that could contain prompt injection (tickets, chat logs, user-generated content)
Freshness and decay management
Operational knowledge rots faster than product docs. Your retrieval layer should support:
- “golden runbooks” with an explicit owner and last-reviewed date
- recency weighting (recent incidents get more weight than 18-month-old ones)
- de-duplication and canonicalization (one best version per procedure)
Layer 4: Reasoning Engine (LLMs, Agents, and Hypothesis-Driven Diagnosis)
AI SRE does not mean “let the LLM decide.” It means “make a reasoning loop that is evidence-bound.”
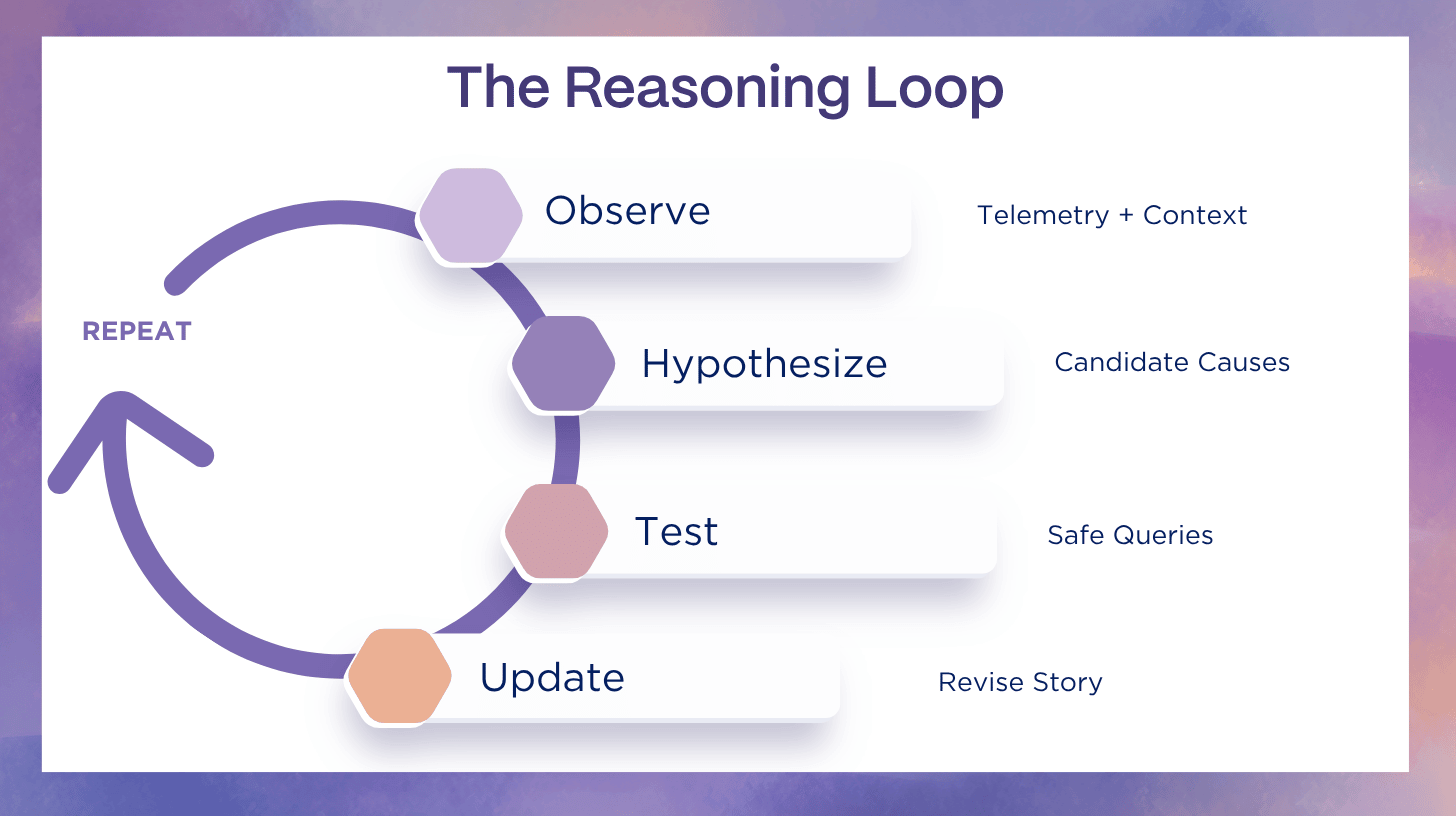
A production-grade loop has these properties:
- falsifiable hypotheses (what evidence would disprove this?)
- tool-mediated testing (query the systems, do not guess)
- competing hypotheses (avoid “single-story lock-in”)
- evidence binding (every claim points to a log/metric/trace/change record)
Tool calling and parallel investigation
The architectural win is parallelism:
- check deploy timeline while validating error budget burn
- compare upstream latency and downstream saturation
- test “flag flipped” and “DB pool exhausted” hypotheses simultaneously
That is how you compress the early incident phase where teams normally lose time hunting for context.
Hallucination prevention is architecture, not vibes
You reduce hallucinations by design:
- restrict tools to read-only until approvals exist
- require evidence snippets or references for every conclusion
- force “verification steps” before any recommendation is treated as actionable
Layer 5: Orchestration and Action (Workflow + Controlled Execution)
This is the boundary between “helpful” and “dangerous.” Your workflow engine is the part that makes AI SRE real.
What the workflow engine must do
- manage state (incident lifecycle, step progression)
- enforce idempotency (safe to retry)
- handle timeouts and retries
- write back to the incident timeline
- coordinate approvals and policy checks
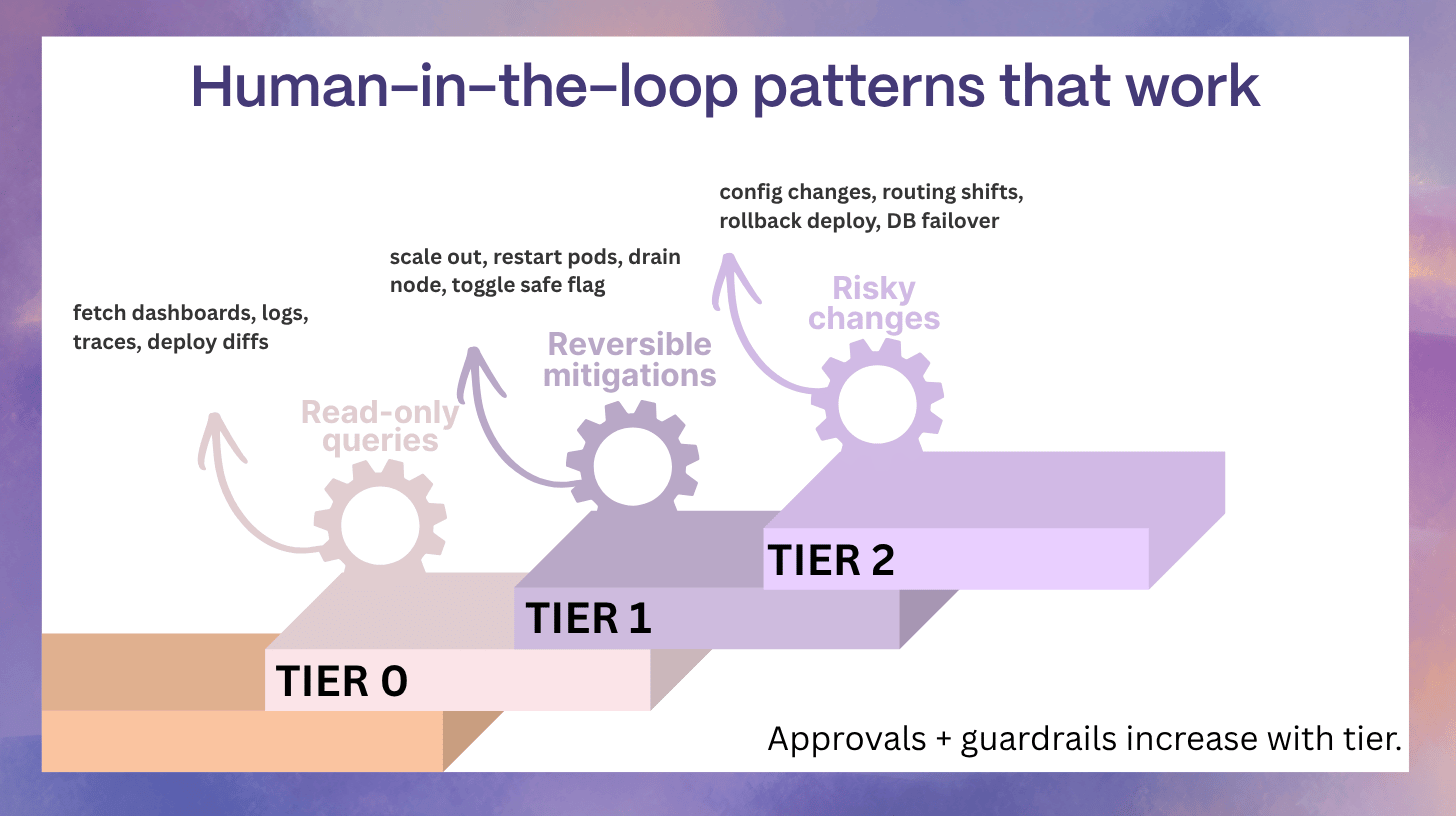
Human-in-the-loop patterns that work
- approve each step for Tier 2 actions
- approve a pre-defined workflow (runbook) for Tier 1 actions
- pre-approve only narrow, reversible auto-remediation with strict stop conditions
This aligns with staged adoption models: read-only, advised, approved, autonomous.
Guardrails by Design (Non-Negotiables)
If you want AI in incident response without trust collapse, the architecture must enforce guardrails.
Control plane essentials
- identity and least privilege (scoped service accounts, short-lived tokens)
- RBAC aligned to team ownership and environments
- policy-as-code for what actions are allowed, where, and when
- immutable audit trails for every query, recommendation, approval, and action
Safety plane essentials
- verification gates (did the metric improve?)
- canary-first execution (small blast radius before broad change)
- rollback automation (fast revert is part of the plan, not a scramble)
- stop conditions (rate limits, error budget thresholds, anomaly escalation)
These controls are also what make AI SRE compatible with enterprise governance and compliance requirements.
Data and Integration Requirements (Minimum Viable Architecture)
You do not need perfection to start, but you do need a minimum set of reliable inputs.
Minimum viable data checklist
- consistent service identifiers and environment tags
- deploy and change tracking (CI/CD, config, feature flags)
- incident objects with timeline events (paging, assignments, comms)
- service ownership and on-call mapping
- a small set of trusted runbooks and recent postmortems
Typical integration map
- observability: Datadog, New Relic, Grafana, Honeycomb
- on-call and incident: paging tools and incident workflows
- collaboration: Slack, Teams
- ticketing: Jira, Linear, ServiceNow
- delivery and change: GitHub/GitLab, CI/CD, feature flags
Reference Architectures You Can Copy
Reference A: Read-only copilot (fastest path to value)
Goal: reduce time-to-context without any action risk.
- builds incident narratives and timelines
- correlates symptoms with recent changes
- drafts comms updates
- suggests safe next checks
Best for: teams building trust and data hygiene first.
Reference B: Assisted actions with approvals
Goal: run verified, repeatable mitigations faster.
- guided runbooks with one-click execution
- approvals captured in the incident record
- audit trails for every action
- verification gates after each step
Best for: mature teams with stable runbooks and clear ownership.
Reference C: Guardrailed autonomy for narrow failure modes
Goal: self-heal routine incidents without surprises.
- only pre-defined incidents
- reversible actions only
- automatic rollback and stop conditions
- continuous evaluation of success rates
Best for: high-volume, well-instrumented systems where a small set of failure modes repeat.
How Architecture Changes Across the Incident Lifecycle
You are not re-teaching incident response here. You are designing what AI changes.
Detection and triage
AI assembles:
- what broke, where, and who is impacted
- whether this is new or similar to a past incident
- which recent changes correlate
Diagnosis and escalation
AI accelerates:
- ownership inference and routing
- dependency-aware impact propagation
- hypothesis generation that is linked to evidence
Comms and coordination
AI improves:
- consistent updates with the same facts across channels
- status-page drafts that match internal truth
- timeline capture as the incident evolves
Remediation and verification
AI enforces:
- safe action sequencing
- verification gates
- rollback readiness
Post-incident learning
AI can:
- produce structured timelines
- suggest prevention tasks grounded in evidence
- update runbooks with what actually worked
How to Evaluate an AI SRE Architecture Without Getting Fooled by Demos
Architecture quality metrics
- time-to-context (how fast responders get a coherent story)
- hypothesis accuracy (how often the first two hypotheses are useful)
- verification pass rate (actions that measurably improve the incident)
- rollback frequency (and whether rollback is fast and safe)
Safety and governance metrics
- prevented unsafe actions (policy blocks that saved you)
- approval latency by action tier
- audit completeness (no “black box” steps)
Business context reminder
When downtime can average thousands of dollars per minute, even small reductions in time-to-context and time-to-mitigation can be economically meaningful.
Pitfalls and Anti-Patterns
- Chat over dashboards with no control plane
- Unbounded tool access (the model can “do anything”)
- Stale runbooks treated as truth
- No verification loop (recommendations become actions by inertia)
- Autonomy-first adoption (trust collapses after the first wrong blast)
Implementation Blueprint (Architecture Checklist)
First 30 days (foundation)
- standardize service identifiers and tags
- integrate deploy, config, and flag change events
- create a small “trusted runbook” set with owners
- build read-only retrieval and incident narrative output
Days 31–60 (workflows + governance)
- introduce workflow engine state and approvals
- define action tiers and policies by environment
- add audit logging that ties actions to incident timeline
- add verification gates for mitigations
Days 61–90 (assisted actions, limited autonomy pilots)
- implement Tier 1 mitigations with approvals
- pilot narrow auto-remediation with hard stop conditions
- track action success rate and rollback rate
- expand runbook coverage based on real incident frequency
FAQs
What data does AI SRE need access to?
At minimum: telemetry plus change history plus service ownership plus incident timelines. Without change and ownership context, diagnosis becomes guesswork.
How do we prevent hallucinations from causing bad actions?
Bind conclusions to evidence, restrict tools, require verification, and gate risky actions behind approvals and policy checks.
Can AI SRE work in regulated environments?
Yes, if your architecture isolates sensitive data, enforces least privilege, and produces auditable records of access and actions.
What is the minimum architecture to get value?
A read-only copilot with reliable topology, change tracking, and retrieval over trusted runbooks and recent incidents.
How do we scope auto-remediation safely?
Only for narrow, reversible failure modes with clear success signals, canary execution, rollback, and stop conditions.
Turn Architecture Into Operational Reality
AI SRE architecture works when it is designed as a controlled incident workflow, not a chat layer on top of dashboards. The winning pattern is consistent across environments: start with a strong data foundation (telemetry plus change history), keep topology and ownership accurate enough to route the right context instantly, and add retrieval so the system can reuse proven knowledge instead of inventing answers. From there, the AI layer becomes a practical reasoning engine that forms hypotheses, runs safe tests, and updates the incident narrative with evidence.
What separates serious AI SRE from demos is governance. A mature AI SRE design includes a control plane (identity, RBAC, approvals, audit, policy) and a safety plane (verification gates, canaries, rollback, stop conditions) so teams can move quickly without creating new risk. Trust is earned in stages: begin with read-only assistance to reduce time-to-context, graduate to assisted actions with approvals, and reserve autonomy for narrow, reversible failure modes that are well-instrumented and rollback-ready.
At Rootly, we help teams operationalize this approach across the incident lifecycle so our customers can turn evidence into faster, safer decisions with verification, approvals, and auditability built in. Book a demo to see how we put AI SRE architecture into practice.