




.svg)









On-call work sits at the intersection of technical reliability and human endurance. As systems grow more complex and always-on expectations become normalized, the sustainability of on-call programs has become a defining factor in whether engineering teams thrive or quietly burn out.
A strong on-call culture is not measured only by fast recoveries or low downtime. It is measured by whether teams can sustain high-quality response over months and years without accumulating fatigue, resentment, or fragile knowledge silos. Organizations that fail to design for sustainability often see higher incident rates, slower recovery over time, and increased attrition among their most experienced engineers.
Key Takeaways
- Sustainable on-call cultures are intentionally designed, not inherited
- Training reduces cognitive load before incidents happen
- Debriefs should strengthen systems, not scrutinize individuals
- Engineer wellbeing directly affects reliability outcomes
- Healthy on-call programs reduce repeat incidents and team turnover
Defining Sustainable On-Call at the System Level
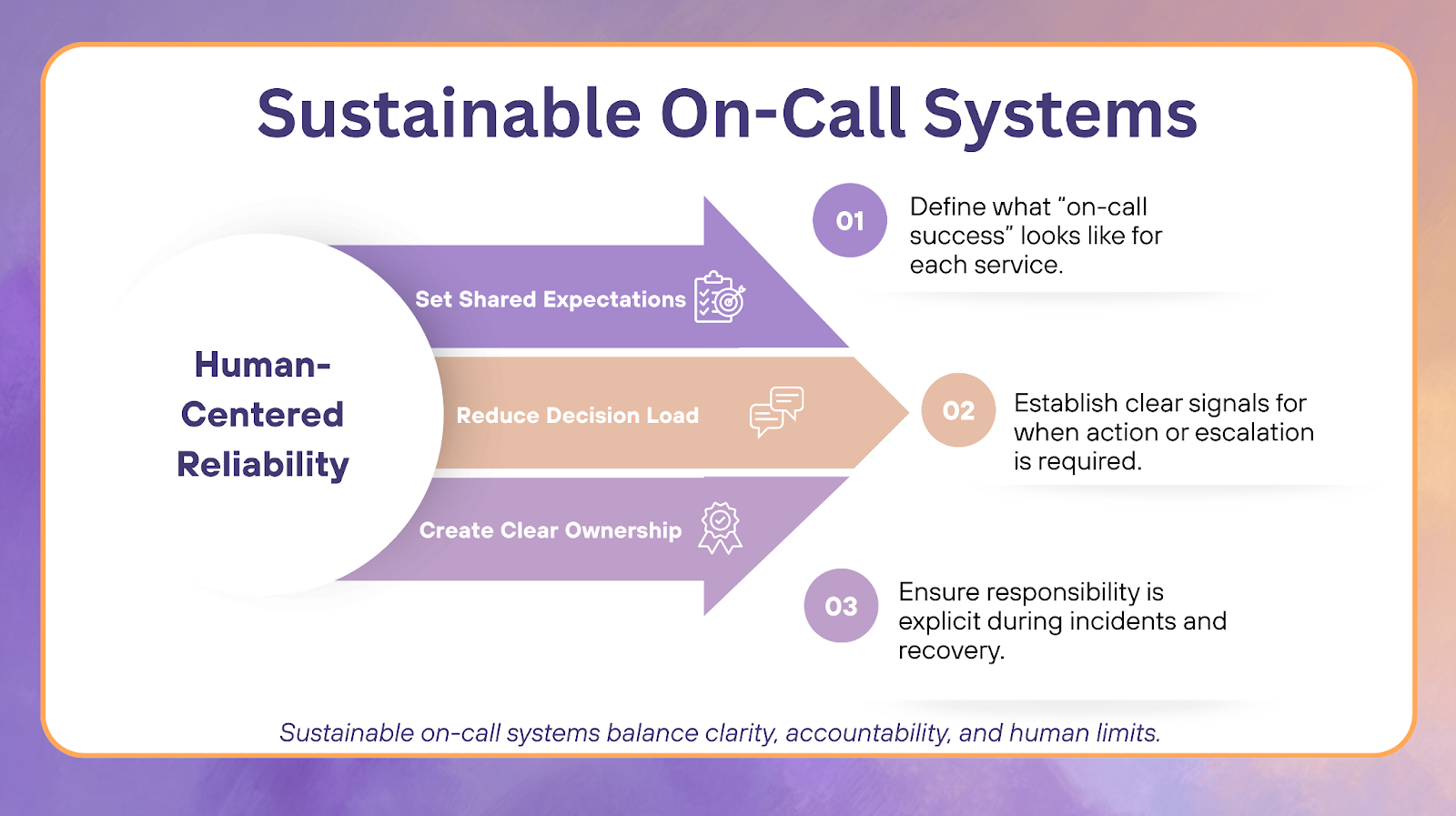
Sustainable on-call means teams can respond to incidents repeatedly without accumulating long-term fatigue, increased attrition, or erosion of system knowledge.
Sustainability in on-call work is often misunderstood as a scheduling or compensation problem. In practice, it reflects whether the surrounding systems enable humans to make sound decisions under pressure without degrading performance, confidence, or judgment over time.
A sustainable on-call culture treats reliability as a human systems challenge. It balances uptime expectations with cognitive limits, recovery needs, and learning capacity. Teams operating within sustainable on-call systems respond more consistently, avoid cascading errors, and preserve institutional knowledge as systems evolve.
The Real Risks of Poor On-Call Culture
Poor on-call culture increases incident frequency, slows recovery, and accelerates burnout and team turnover.
When on-call systems are poorly designed, engineers experience chronic sleep disruption, persistent alert anxiety, and a growing sense of personal responsibility for systemic failures. Over time, this erodes attention, confidence, and decision quality, leading to behaviors that quietly increase operational risk.
Common consequences of unhealthy on-call culture include:
- Chronic sleep deprivation that impairs judgment, memory, and reaction time
- Alert fatigue caused by excessive or non-actionable notifications
- Slower incident detection and recovery due to hesitation or delayed escalation
- Avoidance behaviors such as silencing alerts or deprioritizing off-hours response
- Increased emotional strain from feeling individually accountable for system failures
- Knowledge loss as experienced engineers disengage or leave the organization
Organizations often misinterpret these outcomes as individual performance problems rather than failures of system design, alerting strategy, or workload distribution. This misalignment creates a reinforcing cycle where incidents increase, trust deteriorates, and response capacity weakens as experienced engineers exit or disengage.
Training as the Foundation of On-Call Resilience
On-call training should reduce uncertainty during incidents, not rely on individual heroics.
Effective on-call training prioritizes decision readiness over tool familiarity alone. Engineers must understand not only how systems function in steady state, but how to reason, prioritize, and act when those systems behave unpredictably under stress.
High-performing teams invest in training methods that build confidence before real incidents occur. These approaches help engineers form durable mental models that hold up under pressure and reduce cognitive overload during live response.
Core components of effective on-call training include:
- Scenario-based incident simulations that mirror real failure patterns
- Shadow rotations that allow gradual exposure without full responsibility
- Clear, principle-driven runbooks that support judgment rather than rigid scripts
- Training on escalation timing and ownership clarity
- Communication practice for internal teams and external stakeholders
- Post-incident learning loops that reinforce training through real outcomes
When training addresses both technical and human decision-making skills, on-call response becomes faster, calmer, and more consistent. Teams rely less on improvisation and heroics, and more on shared understanding and practiced response patterns.
Designing On-Call Rotations That Humans Can Sustain
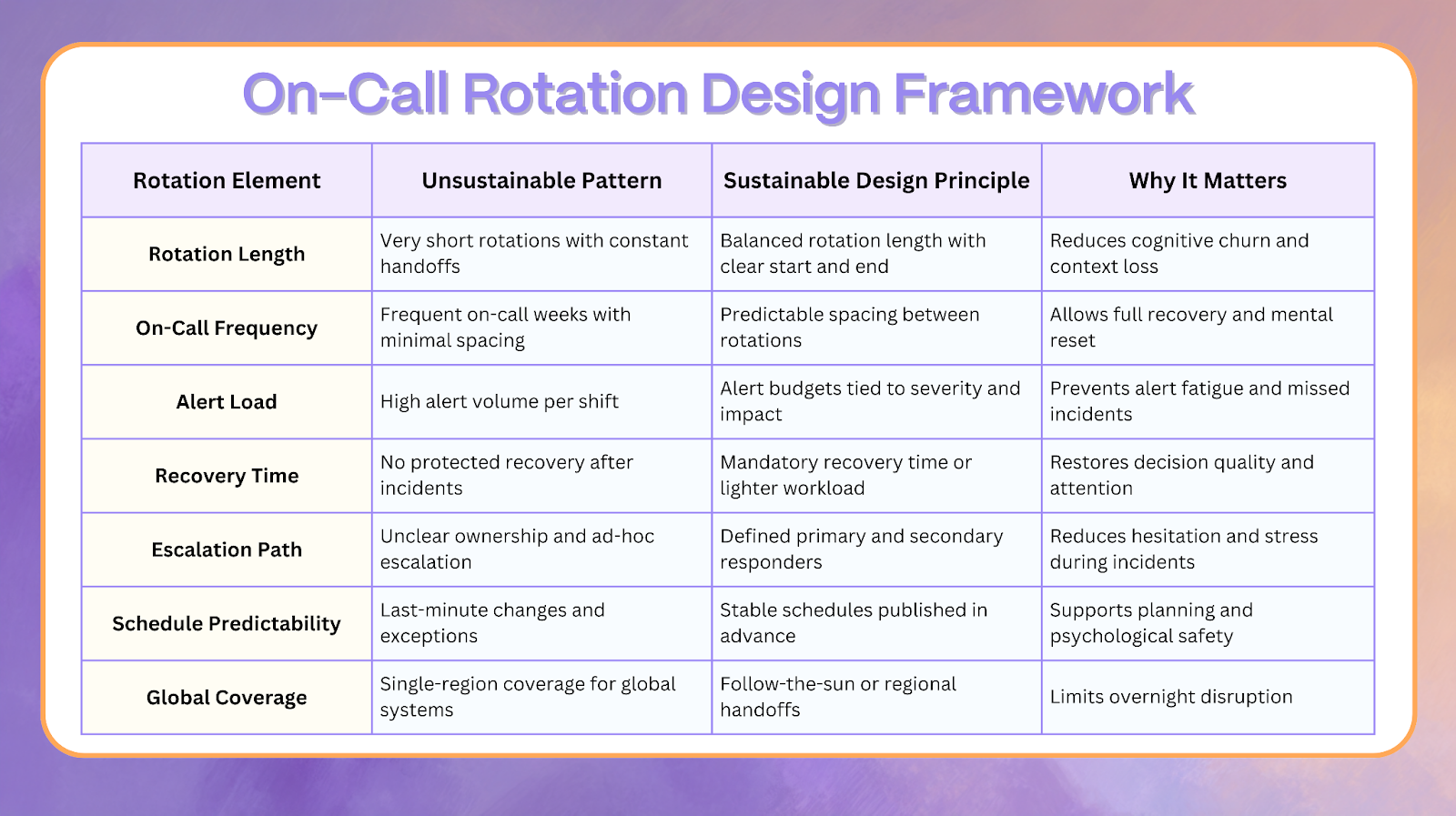
Rotation design directly determines alert quality, recovery speed, and emotional exhaustion.
Rotation length, frequency, and recovery time matter more than many organizations realize. Short rotations with frequent interruptions prevent deep recovery, while overly long rotations concentrate fatigue.
Sustainable programs prioritize predictability and fairness. Engineers should know when they are on call, how escalations work, and when they can fully disconnect. Follow-the-sun models, secondary responders, and protected recovery days reduce the cumulative toll of after-hours work.
Alerting Strategy as a Human Factors Problem
Every alert interrupts cognition and should justify that cost.
Alerts are not neutral signals. Each alert disrupts attention, increases stress, and carries a decision burden. Sustainable on-call systems treat alerting as a human factors discipline, not just a monitoring configuration.
Actionable alerts tied to user impact build trust and reduce fatigue. Noisy alerts erode confidence and lead to slower response when real incidents occur. Teams should regularly review alert volume per engineer and retire alerts that no longer serve a clear purpose.
Debriefs That Strengthen Systems Instead of Blaming People
Effective debriefs focus on system behavior under stress, not individual mistakes.
Blameless debriefs do not eliminate accountability. They shift accountability toward systems, assumptions, and constraints. The purpose is to understand why decisions were reasonable at the time, given the signals, tooling, and information available during the incident.
Well-run debriefs turn incidents into durable improvements rather than documentation exercises. They create shared understanding and prevent the same failure patterns from recurring.
Effective debriefs consistently include:
- A clear incident timeline that reflects how events unfolded in real time
- Documentation of signals, alerts, and information available to responders
- Analysis of decision paths and tradeoffs made under pressure
- Identification of system constraints that shaped outcomes
- Explicit separation of system failures from individual actions
- Concrete follow-up actions such as alert tuning, runbook updates, or architectural changes
- Ownership and timelines for implementing improvements
Without visible follow-through, debriefs lose credibility and psychological safety erodes. When learning consistently leads to change, teams engage more deeply, trust the process, and improve response quality over time.
Empathy and Psychological Safety in On-Call Teams
Psychological safety enables on-call teams to act decisively during incidents without fear of blame, hesitation, or personal fallout.
On-call environments amplify stress, uncertainty, and time pressure. In these conditions, empathy and psychological safety are not soft skills. They are operational requirements. Teams must feel safe to escalate early, make imperfect decisions, and ask for help without fear of judgment or reprisal.
Psychological safety extends beyond post-incident debriefs into daily interactions, handoffs, and leadership behavior. When teams trust that mistakes will be examined at the system level, they spend less time defending decisions and more time restoring service. Empathy reinforces this trust by recognizing the human cost of disruption, including sleep loss, cognitive overload, and emotional strain.
The Five Conditions That Sustain Psychological Safety in On-Call Teams
This framework adapts proven team dynamics research to the realities of incident response and on-call work.

How Psychological Safety Shows Up During Incidents
- Engineers escalate issues earlier instead of waiting for certainty
- Team members ask for help without fear of appearing incompetent
- Decisions are made based on available signals, not fear of hindsight blame
- Communication stays focused on resolution rather than self-protection
- Learning continues even during high-severity events
When psychological safety is absent, teams default to risk-avoidant behaviors that slow response and increase damage.
Leadership Behaviors That Reinforce Psychological Safety
- Treat near-misses as learning opportunities, not failures
- Publicly support engineers who escalate early, even when impact is limited
- Separate incident outcomes from performance reviews
- Model calm, respectful communication during high-pressure events
- Ensure follow-through on debrief action items
Psychological safety is created through repeated signals, not policy statements. Engineers learn what is truly safe by observing how leaders respond when things go wrong.
Wellbeing as an Operational Dependency
Team wellbeing directly influences incident response quality and system stability.
Sleep deprivation impairs judgment, memory, and reaction time. Chronic stress increases error rates and reduces creative problem-solving. These are not personal wellness issues; they are operational risks.
Organizations that treat wellbeing as optional often experience higher incident recurrence and lower engagement. Sustainable programs normalize recovery time, offer mental health support, and acknowledge the emotional impact of high-severity incidents without stigma.
Leadership’s Role in Sustaining On-Call Culture
Leaders shape on-call culture through priorities, language, and follow-through.
Leadership behavior sets the tone for how on-call is experienced. When leaders reward heroics, ignore recovery needs, or push unrealistic reliability promises, they create silent pressure that erodes sustainability.
Effective leaders model healthy escalation, protect teams from unnecessary interruptions, and ensure reliability goals align with staffing and system maturity. They treat on-call health as a shared responsibility, not an individual burden.
Metrics That Actually Indicate On-Call Health
Sustainable on-call programs track human and system metrics together.
Traditional metrics like uptime and mean time to recovery are incomplete. Sustainable programs also track alert volume, after-hours interruption rates, incident recurrence, and retention trends.
Qualitative feedback from engineers often reveals issues before metrics do. Regular reviews that combine data with lived experience help teams adjust before burnout becomes visible attrition.
Building Continuous Improvement into On-Call Systems
Sustainable on-call culture evolves through feedback, iteration, and shared ownership.
On-call systems should be treated as living systems rather than static schedules. As teams grow, architectures change, and incident patterns shift, the assumptions behind coverage, alerting, and response must be continuously re-evaluated. What worked six months ago may quietly introduce friction or fatigue today if left unchanged.
The strongest results emerge when teams regularly review on-call health, rotate ownership of reliability improvements, and deliberately retire practices that no longer serve responders. By treating on-call as an evolving system instead of a fixed obligation, organizations build resilience that compounds over time and supports both reliable systems and sustainable teams. At Rootly, we support this approach by helping teams operationalize continuous improvement across on-call and incident response. To see how this works in practice, book a demo.
Frequently Asked Questions
How large should an on-call culture be to remain sustainable?
A sustainable on-call culture typically requires at least 6 to 8 engineers participating in the rotation. At this size, on-call responsibility is distributed in a way that allows meaningful recovery between shifts and prevents chronic fatigue. When fewer people carry the load, on-call becomes a constant presence rather than a temporary responsibility, which erodes trust and increases burnout. Larger participation also strengthens culture by normalizing shared ownership and preventing reliability knowledge from concentrating in a small group. As systems grow more complex, expanding participation becomes a cultural necessity rather than a staffing preference.
How does documentation shape on-call culture over time?
Documentation directly shapes whether on-call culture feels safe, repeatable, and learnable. When expectations, system behavior, and response patterns are clearly documented, engineers spend less time guessing and more time acting with confidence. Over time, this reduces stress, shortens incidents, and reinforces a culture where success is defined by shared understanding rather than individual heroics. Poor or missing documentation shifts cultural pressure onto individuals, creating environments where only a few people feel capable of responding effectively, which undermines long-term sustainability.
Should junior engineers be part of a healthy on-call culture?
Yes, junior engineers should be included once the culture supports learning rather than punishment. Healthy on-call cultures treat participation as a developmental milestone, not a test of endurance. When training, shadowing, and escalation support are built into the system, junior engineers gain confidence without increasing operational risk. Excluding them delays learning and reinforces unhealthy dynamics where responsibility accumulates on senior staff, eventually leading to fatigue and disengagement.
How can teams understand cognitive load as a cultural signal?
Cognitive load becomes a cultural signal when decision-making feels consistently stressful, rushed, or isolating. Teams experience rising cognitive load when alerts demand complex reasoning, interruptions are frequent, or responders lack clear guidance. Over time, this shapes culture by encouraging hesitation, delayed escalation, or avoidance behaviors. Teams that pay attention to how incidents feel, not just how fast they resolve, gain earlier insight into cultural strain and can correct course before burnout appears.
When does on-call culture need to be intentionally redesigned?
On-call culture needs redesign when reliability depends on endurance rather than systems. This point is reached when engineers report persistent fatigue, incidents repeat despite postmortems, or response quality declines even as teams gain experience. Cultural redesign is also required when organizations grow, architectures change, or expectations increase without adjusting on-call structures. Treating on-call culture as fixed leads to silent degradation, while regular redesign preserves trust, learning, and long-term resilience.