




.svg)









It’s 2:47 a.m. Your phone buzzes. Rootly again. You peel yourself out of bed, squinting at the alert. Another database failover. You’ve been here before, you fixed this exact issue last week. You know exactly what the runbook says, but your brain is foggy, your patience thin, and your motivation almost nonexistent.
By the time the cluster stabilizes, it’s 4:00 a.m. Your alarm for standup will go off in four hours. And after that? A backlog of Linear issues waiting for you, a planning meeting, a feature launch deadline. You’ll push through like always, but the truth is: you’re running on fumes.
If this sounds familiar, you’re not alone. This is the life of countless SREs and on-call engineers around the world. And it’s one of the biggest threats to reliability that nobody likes to talk about: burnout.
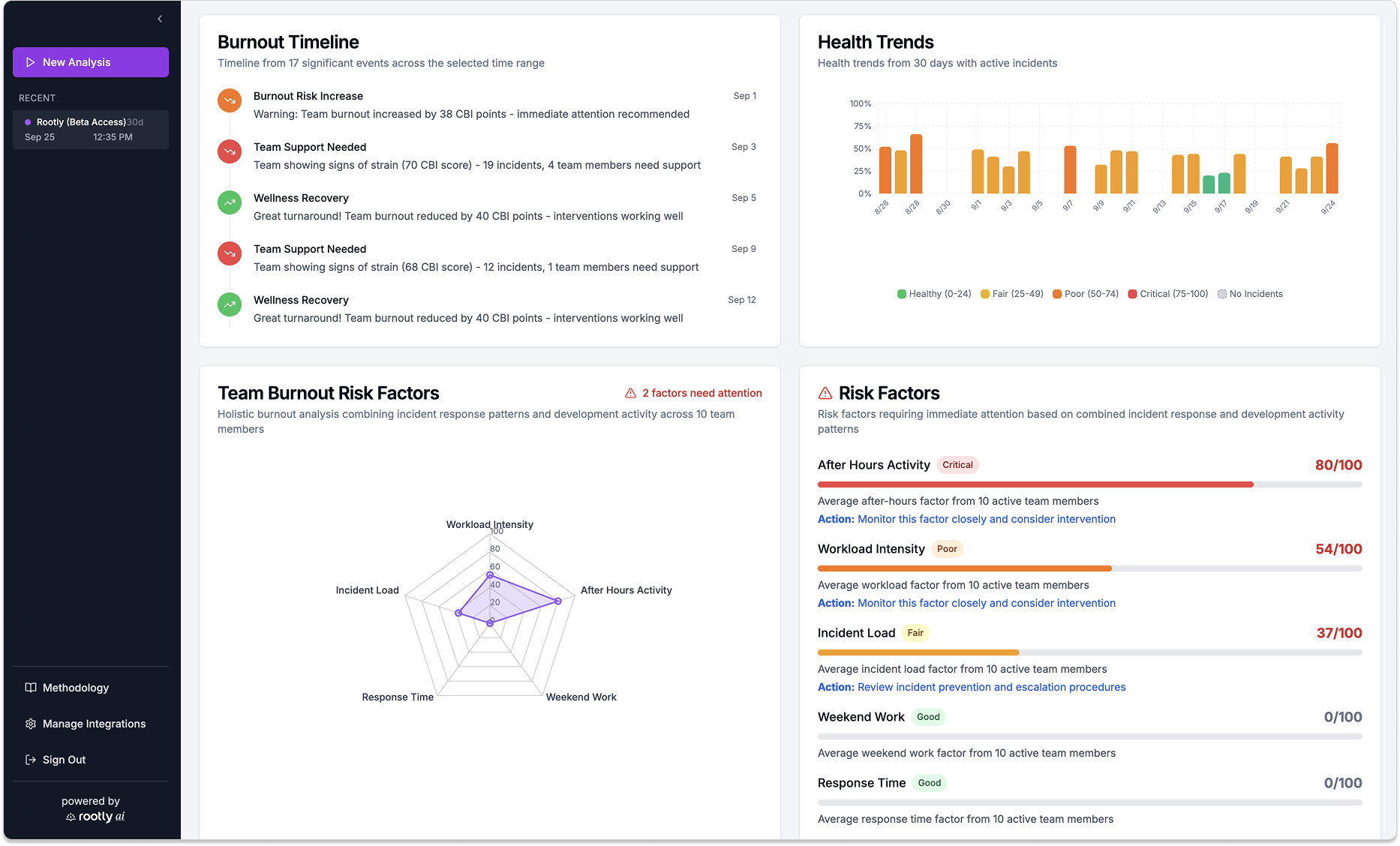
Introducing the Burnout detector for on-call engineers
At Rootly, we’ve spent years helping teams streamline incident response. But we kept seeing the same pattern: even with great tooling, engineers are still burning out. That’s why we built something new.
Introducing On-call Health for on-call engineers. It's a way to put visibility around the health of your team, not just your systems. Now available in beta for testing.
How does it work
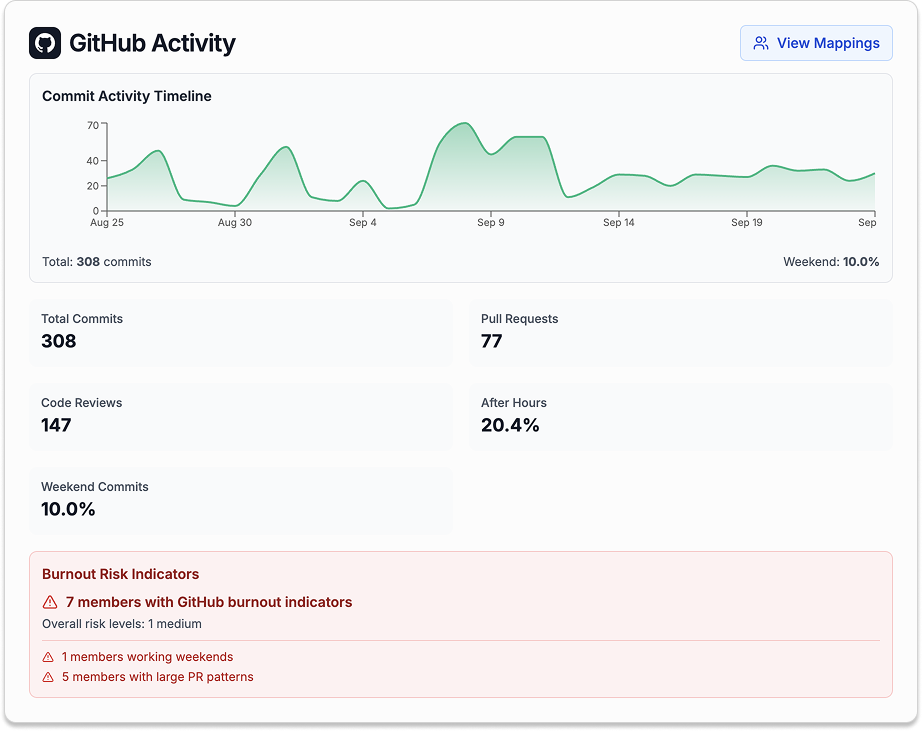
The On-call Health tool meets you where you are. It is compatible with Rootly and PagerDuty, and it also reads signals from GitHub and Slack.
- Connect your tools: Integrate with Rootly and other incident response tools' incident data, GitHub activity, and Slack communication.
- Analyze patterns: It looks at workload pressure, after-hours activity, escalation frequency, response times, and even sentiment in team communications.
- Adapt to your environment: Whether you’re a 20-person startup or a global enterprise, the system calibrates based on your data.
- Generate interventions: It surfaces Risk-Based Recommendations—whether that means rotating schedules, reducing workloads, or offering recovery time.
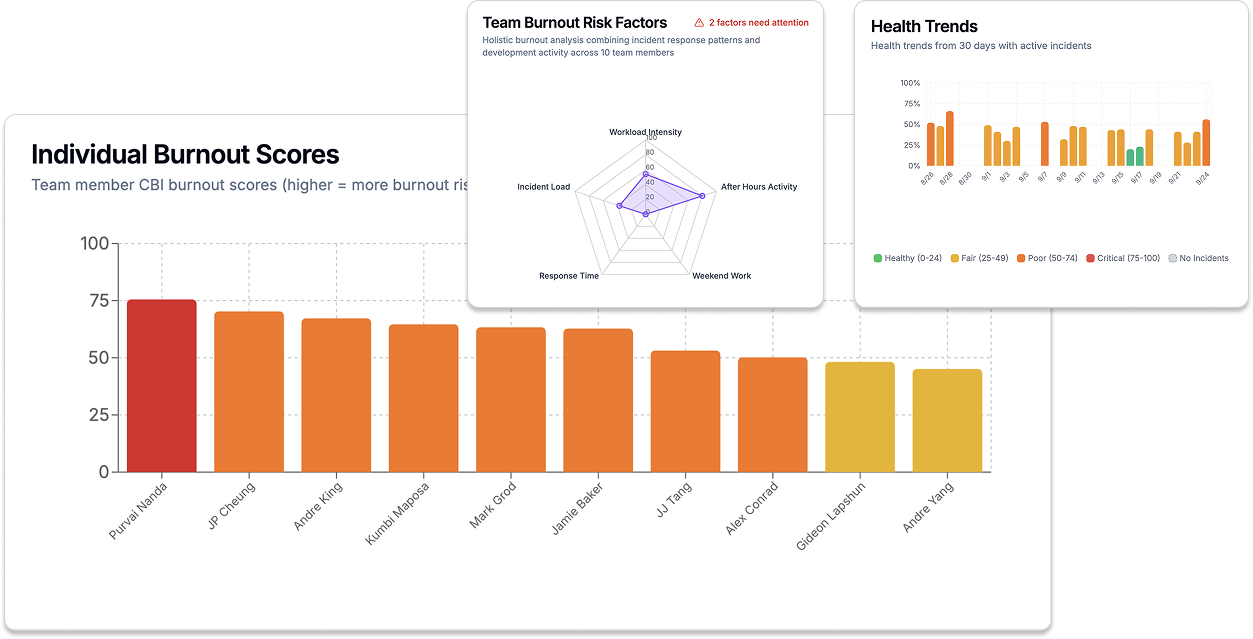
Our system takes inspiration from validated research, including the Copenhagen Burnout Inventory (CBI) and the Maslach Burnout Inventory (MBI), widely regarded as gold standards for measuring workplace burnout. While our tool isn’t intended for diagnosis, neither is a medical tool, it provides signals that can alert managers when something may be off on their team.
Why this matters for SREs
Think of it like this: just as you wouldn’t run a cluster without monitoring CPU or memory usage, you shouldn’t run a team without monitoring for burnout risk.
- Quantify burnout risk → Signal who might be overwhelmed.
- Proactively rebalance rotations → Prevent disasters before they happen.
- Back leadership decisions with data → When you tell execs your team needs a lighter rotation, you’ll have evidence to prove it.
Burnout isn’t a “soft” issue, it’s a reliability issue. And like any other reliability issue, the best fix is catching it early.
Getting started
We’ve made it simple to try:
- Hosted version → oncallburnout.com for a fully managed experience.
- Open source version → Rootly-AI-Labs on GitHub if you’d rather self-host and customize.
Our project is still in beta mode, expect some rough edges.
A rapidly evolving project
We're adding more features based on feedback from teams using On-call Health. A sneak peak of what's coming in the following days:
Survey-based check ins


Permissions management

The reality of on-call work
On-call is one of the most unique stressors in tech. Unlike feature development or code review, it doesn’t respect your working hours. It doesn’t care about your weekend plans or your sleep cycle. Systems fail when they fail, and SREs are the human safety net.
But while systems can be scaled, automated, and tuned, humans aren’t so flexible. We can’t keep running hot indefinitely. Yet too many organizations treat on-call as an infinite resource, expecting engineers to handle incident after incident without recognizing the toll it takes.
Let’s break down why on-call is such a fertile ground for burnout.
Why on-call burns engineers out
1. High alert volume → alert fatigue
Every engineer has faced noisy alerts. Metrics set too tightly, overlapping rules, or signals that rarely require real action. When every Slack ping or on-call ring could be either “the world is on fire” or “CPU is 75% for 30 seconds,” your nervous system stops distinguishing. That constant vigilance wears you down.
2. Unpredictable hours → sleep deprivation
Humans need sleep cycles. But an on-call rotation doesn’t care if you’ve just fallen asleep or if it’s your kid’s birthday dinner. Repeatedly losing sleep or being forced to work at odd hours builds up debt, not just in your health, but in your patience and resilience.
3. No recovery time → chronic stress
Your system just went through a noisy autoscaling storm all night, spiking CPU and churning logs at 10x normal volume. In the morning, you’d never expect that system to immediately handle peak traffic without cooldown. That’s what many engineers face: handle an incident at 3 a.m., then be expected to “deliver” on regular sprint commitments during the day. Without recovery windows, stress compounds fast.
4. Recurring incidents → learned helplessness
There’s nothing more soul-crushing than fixing the same issue over and over. Toil, technical debt, and repeated incident patterns erode your sense of progress. Instead of solving problems, you’re just duct-taping the same ones.
5. Cultural blind spots → silence
Finally, there’s culture. Too often, burnout is dismissed as a personal failing: “toughen up,” “it’s part of the job,” or “we all went through it.” This discourages engineers from speaking up, leaving leaders in the dark until attrition forces their hand.
The cost of burnout
Burnout isn’t just a “wellness” problem. It’s a reliability problem. Exhausted engineers make slower decisions, miss subtle signals, and struggle to collaborate effectively during incidents. When the pager goes off, you want someone alert, engaged, and confident responding—not someone who’s running on two hours of sleep and sheer willpower.
Research backs this up: teams facing burnout see reduced productivity, higher error rates, and ultimately higher turnover. Losing seasoned SREs to burnout doesn’t just cost morale, it costs months of recruiting and onboarding, not to mention tribal knowledge that walks out the door.
What SREs have tried so far
The SRE community has long known this. In fact, Google’s original Site Reliability Engineering book explicitly warns against overloading on-call engineers. The recommended rule of thumb: no more than 2–3 incidents per shift. If you’re constantly above that, your system—or your rotation—is unsustainable.
Companies have tried different strategies:
- Smarter alerting → tuning rules, cutting noise, and escalating only true severity-1 events.
- Follow-the-sun rotations → spreading coverage across time zones to minimize night-time pages.
- Blameless retrospectives → encouraging learning rather than punishing mistakes.
- Toil reduction → automating recurring fixes to give engineers time back.
These are essential practices. But they don’t solve one fundamental issue: visibility. You can’t fix what you can’t measure. And burnout, unlike latency or error rates, doesn’t show up on your Grafana dashboards.
Burnout is a reliability risk
SREs are trained to think about failure. They design for redundancy, observability, and graceful degradation. But when it comes to their own teams, they have often left resilience to chance.
The truth is: your people are your most critical system. If your engineers are overloaded, exhausted, or checked out, every other system is at risk.
Rootly On-call Health is about more than dashboards and alerts—it’s about keeping the humans behind reliability sustainable. Because the best incident response isn’t just fast or automated—it’s healthy.
So the next time your pager buzzes at 3 a.m., ask yourself: is my system the only one in need of monitoring, or is it time to put observability around my team too?
Try Rootly On-cal Health today, and give your engineers the same reliability you expect from your systems.





