




.svg)









We take every new frontier model announcement with a grain of salt, since we have often seen models fail to live up to the hype once we test them with SRE tasks. But that is not the case with the latest Gemini 3 Pro mode release by the DeepMind team. After running it through SRE-skills-bench, we found that Gemini 3 Pro was, on average, 4% more accurate than competing models. This is a meaningful improvement at a time when model performance is starting to consolidate.
Let’s dive into the findings and the methodology behind them.
Gemini 3 breaks OpenAI’s winning streak
Since the inception of SRE-skills-bench about seven months ago, OpenAI models have consistently led the pack on SRE-oriented tasks. This has always been a bit surprising to the engineering community, which generally favors Anthropic models for day-to-day development work, and for good reasons. But SRE tasks are different from SWE tasks, and in those workflows, OpenAI models were generally on top. Gemini had always been a solid second or third choice, but it was never close to matching OpenAI’s overall accuracy.
The DeepMind team just changed that. In our tests, Gemini 3 Pro outperformed GPT-5 across all SRE tasks, with the largest difference in S3 security configuration (13%) and IAM configuration (8%). And across our full battery of tests, Gemini 3 Pro ended up about 4% more accurate.
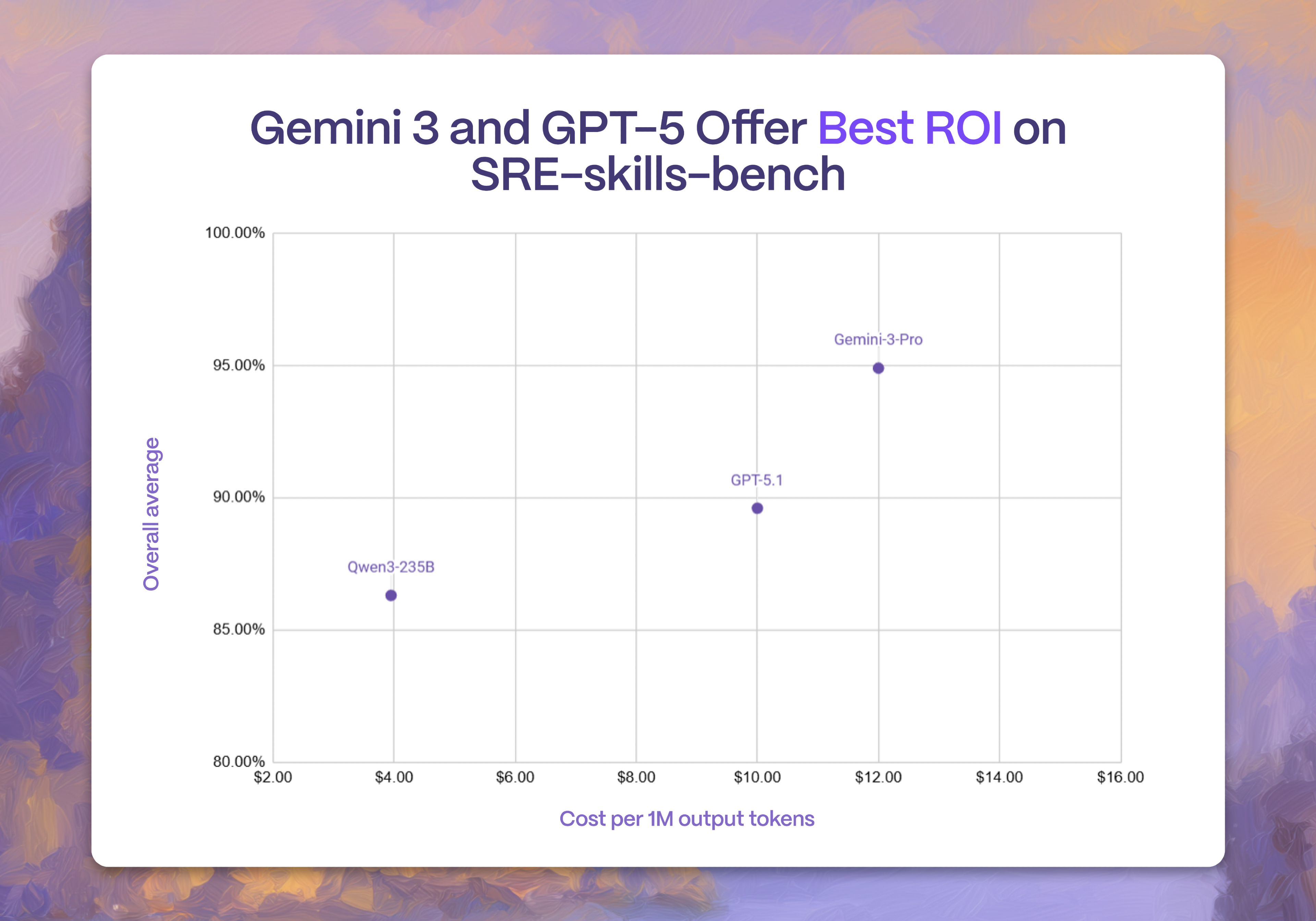
So what’s the tradeoff? Cost. A million tokens of GPT-5 will run you about $10, while Gemini 3 Pro comes in at $12. For some teams, that might not matter much, but at larger volumes, that 20% difference starts to add up.
Benchmark methodology
SRE-skills-bench is an open-source benchmark developed by Rootly AI Labs, we think of it as the SWE-bench for SREs. It answers the question: what's the current best LLM for SREs?
For 9 of our 10 tests, we give models a wide range of Terraform tasks across AWS, GCP, and Azure. For each cloud, the benchmark measures how well the model handles operations across storage, compute, and networking.
The Terraform dataset includes about 500 AWS 535 covering S3, VPC, and IAM operations. GCP includes roughly 600 tests across Network, Compute, and Storage. Azure accounts for the largest share, with nearly 3,000 tests focused on Compute, Networking, and AKS.
The last test in our benchmark is designed to mimic the SRE need to push a hot fix when a change breaks production. For this analysis section, we use a dataset of about 600 GitHub issues from popular open-source projects like Mastodon, ChromaDB, and Tailscale. Each example requires the model to understand the change, analyze the diff, and identify the pull request that would best resolve the issue.
To maintain the integrity of the benchmark and prevent models from training directly on it, we open-source only about 40% of the dataset on our HuggingFace space. The rest remains private and is used strictly for evaluation.
If you are interesting in learning more about the methodology, check out AI Labs Sylvain Kalache and Laurience Liang video on the topic.
Getting started
Our benchmark is fully open source and you can access the source code on the Rootly AI Labs GitHub page.
If you want to replicate our findings or simply benchmark a model we did not benchmark yet, you can quickly get started with a simple command using open-source OpenBench.
# install openbenchuv
pip install openbench
#Set your API key (any provider!)
export GROQ_API_KEY=your_key # or OPENAI_API_KEY, ANTHROPIC_API_KEY, etc.
#Run SRE-skills-bench
benchmarkbench eval gmcq --model "openrouter/google/gemini-3-pro-preview" --T subtask=s3-security-mcqGet involved
The Rootly AI Labs is a community-driven initiative, designed to redefine reliability engineering. We develop innovative prototypes, create open-source tools, and produce research that's shared to advance the standards of operational excellence. Our fellows ranges from seniors with decades of experience at companies like LinkedIn, Venmo, Docker to students from universities like Waterloo and Carnegie Mellon.
If you are interested in contributing to SRE-skills-bench or other open-source projects such as On-call Burnout Detector, get in touch!
Disclaimer: while Google DeepMind supports the Rootly AI Labs. This does not influence our benchmark. All results can be fully replicated using the provided code and dataset.




