




.svg)









SREs should not pick the models they work with based on irrelevant benchmarks or Reddit anecdotes. A recent survey found that 84% of developers use AI tools, and that is no different for SREs. But while there are a lot of benchmarks assessing LLMs on developer-centric tasks, SREs are left in the dust. That’s why the Rootly AI Labs has been developing a benchmark specifically designed for that, adding tests for Terraform, AWS, GCP, and Azure
However, even specialized benchmarks do not tell the whole story. We partnered with Not Diamond to look at how prompt-optimizing for a specific model can impact the performance an LLM has when executing tasks. The Not Diamond team ran optimizations in our benchmark’s prompts for all models, leading to up to 100% performance improvements on Sonnet 4.5 for SRE-oriented tasks.
tldr: GPT-5 still performs best, but we boosted Sonnet 4.5 performance by nearly 2x
While Sonnet-4.5 is among the preferred models for developers, our benchmark found that it did not perform as well as GPT-5 for SRE-related tasks, if we use these models with their default parameters.
However, Not Diamond prompt adaptation platform was able to further boost Sonnet 4.5 performance by up to nearly a 2x improvement in some of our test cases, thereby bridging any significant gaps between different models.
Methodology
The Rootly’s AI Labs open-source benchmark suite for SRE-tasks, already presented at two top-tier machine learning conferences ICML and ACL 2025, is adding new datasets in this edition: Terraform tasks across AWS, GCP, and Azure. For each, the benchmark assess the models capabilities on manipulation of storage, compute and networking.
Our Terraform dataset is spread across multiple providers and sub-categories:
AWS Datasets:
- S3 Security: 69 entries
- VPC NAT: 221 entries
- IAM: 245 entries
GCP Datasets:
- Network: 219 entries
- Compute: 162 entries
- Storage: 258 entries
Azure Datasets:
- Compute: 1,498 entries
- Network: 1,176 entries
- AKS: 235 entries
At the Rootly AI Labs, we evaluated the following tasks on a variety of proprietary and open source models:
- The GitHub Multiple Choice Questions (GMCQ) task from our EFCB suite
- The Azure Kubernetes MCQ from our Terraform Suite
- The AWS S3 Security MCQ from our Terraform suite
Model Evaluation Results
We integrated our evaluation methodology with the OpenBench framework that the evaluation team at Groq developed. In collaboration with the Groq OpenBench team, we added the following evaluations which can now be run in a single terminal command directly from OpenBench, making model benchmarking easy and effortless for SRE tasks.
GMCQ Evaluation Results
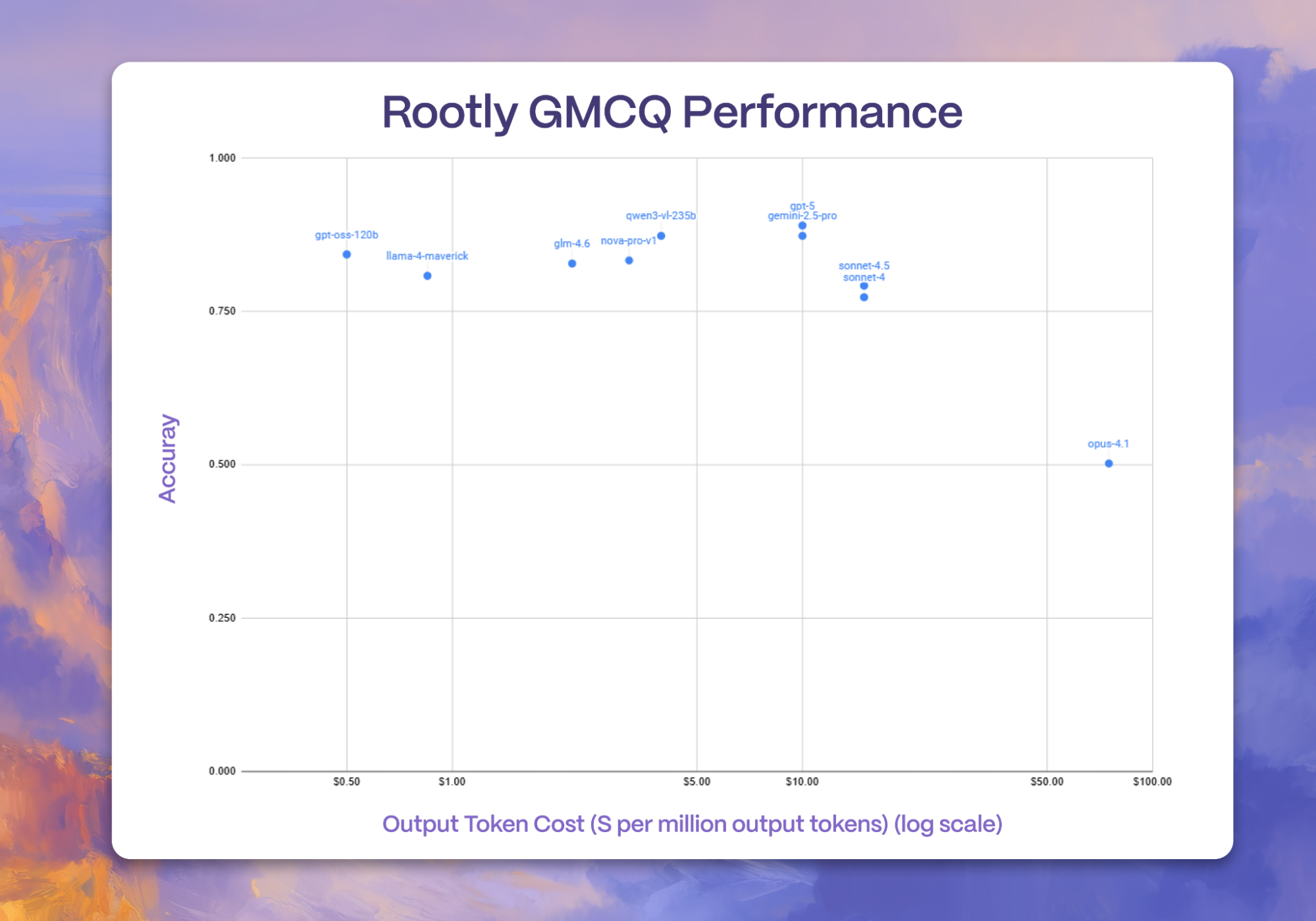
We first evaluated a selection of frontier models on our Rootly GitHub Multiple Choice Questions (GMCQ) task, which is part of our EFCB benchmarking suite. Using Groq’s OpenBench evaluation framework, this GMCQ evaluation set looks at 600 multiple choice questions sourced from six popular GitHub repositories. Each question takes a real-world pull request title and description, and then asks a model which code diff (out of four real-world code diffs from the same repository) successfully resolved that GitHub pull request. As a result, GMCQ allows developers to easily evaluate a model’s ability to understand code and its capacity to identify code diffs that can successfully close issues during development.
As shown in the scatter plot, we notice that Qwen3-vl-235B is the top-performing open-source model, while GPT-5 and Gemini-2.5-Pro are the strongest closed-source models. However, many frontier models are within reach of each other. These results suggest that for many real-world code understanding tasks, it may be more cost-effective to pick and choose smaller or cheaper models to evaluate
Terraform Evaluation Results
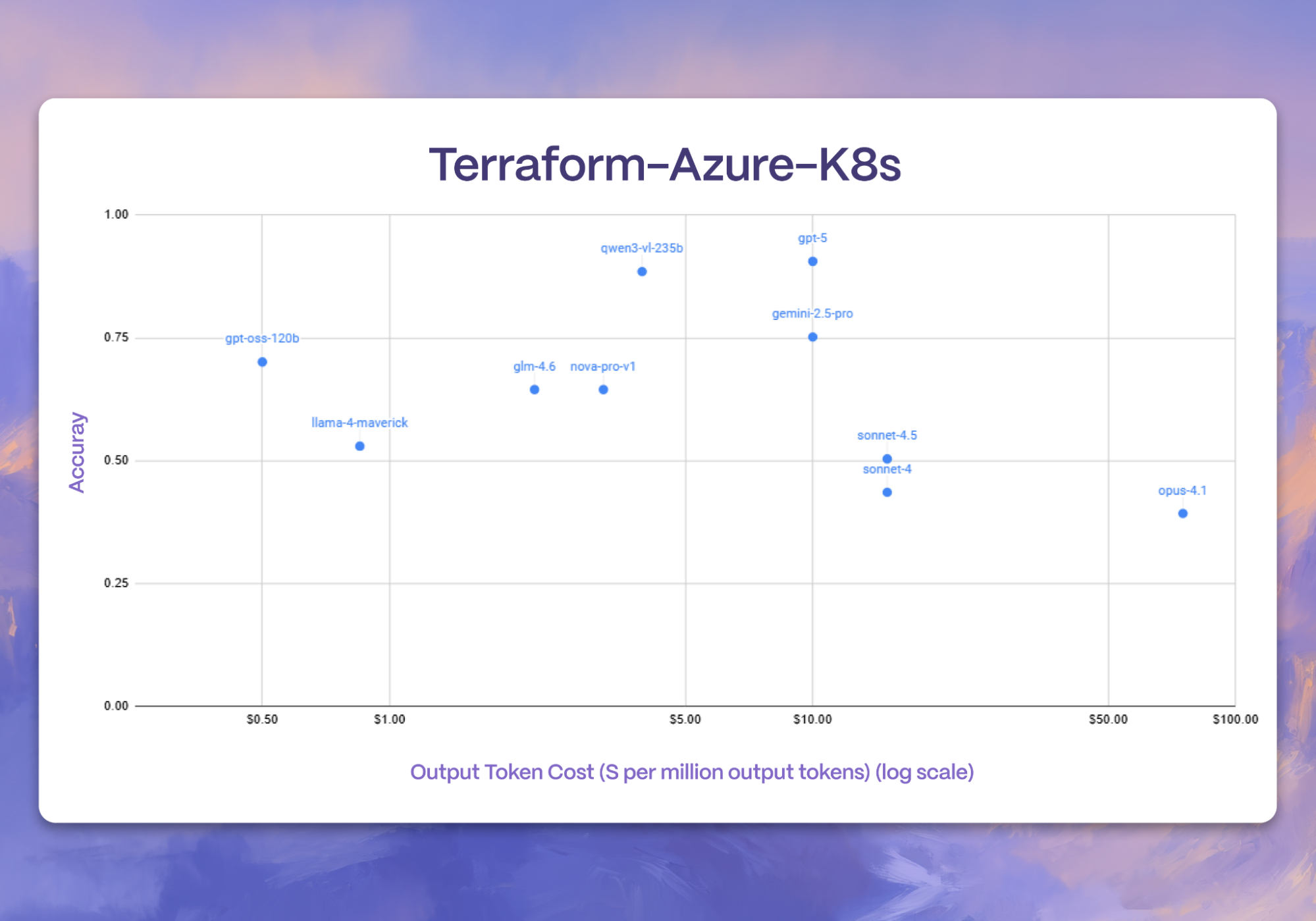
For the first time, we release a new suite of Terraform-based benchmarks focused on evaluating models for SRE tasks. In our Terraform multiple choice benchmark focusing on Kubernetes questions related to Azure, we begin to observe larger gaps compared to the GMCQ subtask. These gaps also persist when we run our SRE Terraform benchmark on these models, where we observe that GPT-5 still tops the closed source models we surveyed, and Qwen-3-235B beats our selection of open source models.
However, we decided to take things one step further to figure out how to boost model performance on these same tasks. We partnered with Not Diamond, where we demonstrate how to close these gaps through Prompt Adaptation as mentioned in the next section.
Boosting Model Performance on SRE Evals with Not Diamond
Choosing the right model is only half the battle. Prompting each model correctly is equally important. As the AI landscape becomes increasingly fragmented, every developer has seen firsthand that prompts written for one model don’t easily transfer to others. Manually rewriting them for every new model that’s released quickly becomes unsustainable as teams scale across a constantly shifting pool of models.
To explore this in the context of SRE workloads, we partnered with the Not Diamond team, who applied their Prompt Adaptation framework to our benchmark datasets. The system uses an agentic prompt-rewriting approach that automatically optimize for different models, improving task accuracy while reducing engineering overhead. In about 30 minutes of background processing, it generates around a thousand prompt variations and selects the best-performing one for each model.
We ran Prompt Adaptation on the newly released Claude 4.5 Sonnet, GPT-5, and Gemini 2.5 Pro, using the same Rootly’s GitHub task (GMCQ) from the EFCB suite and Azure Kubernetes MCQ and AWS S3 Security MCQ tasks from the TerraForm Suite.
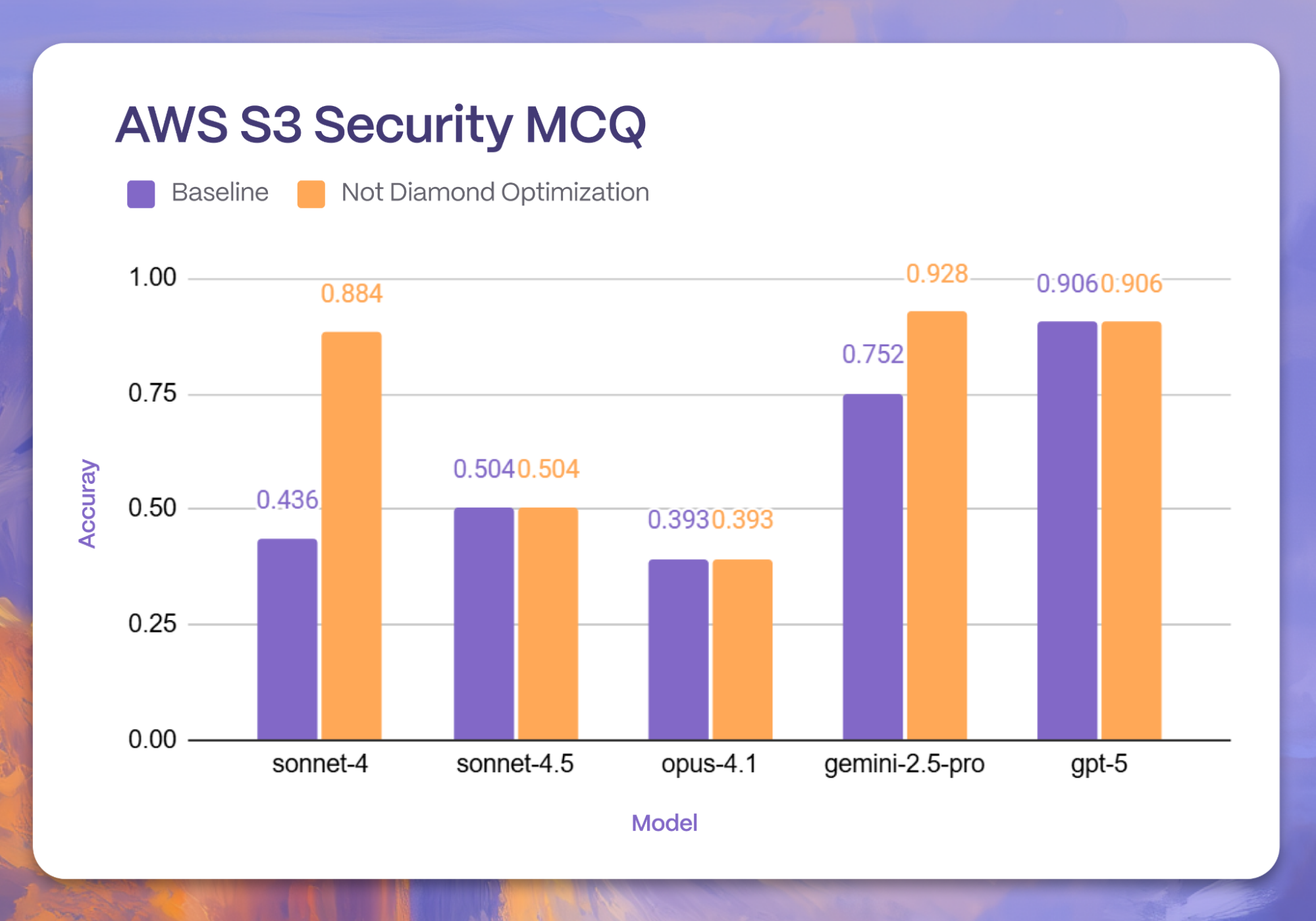
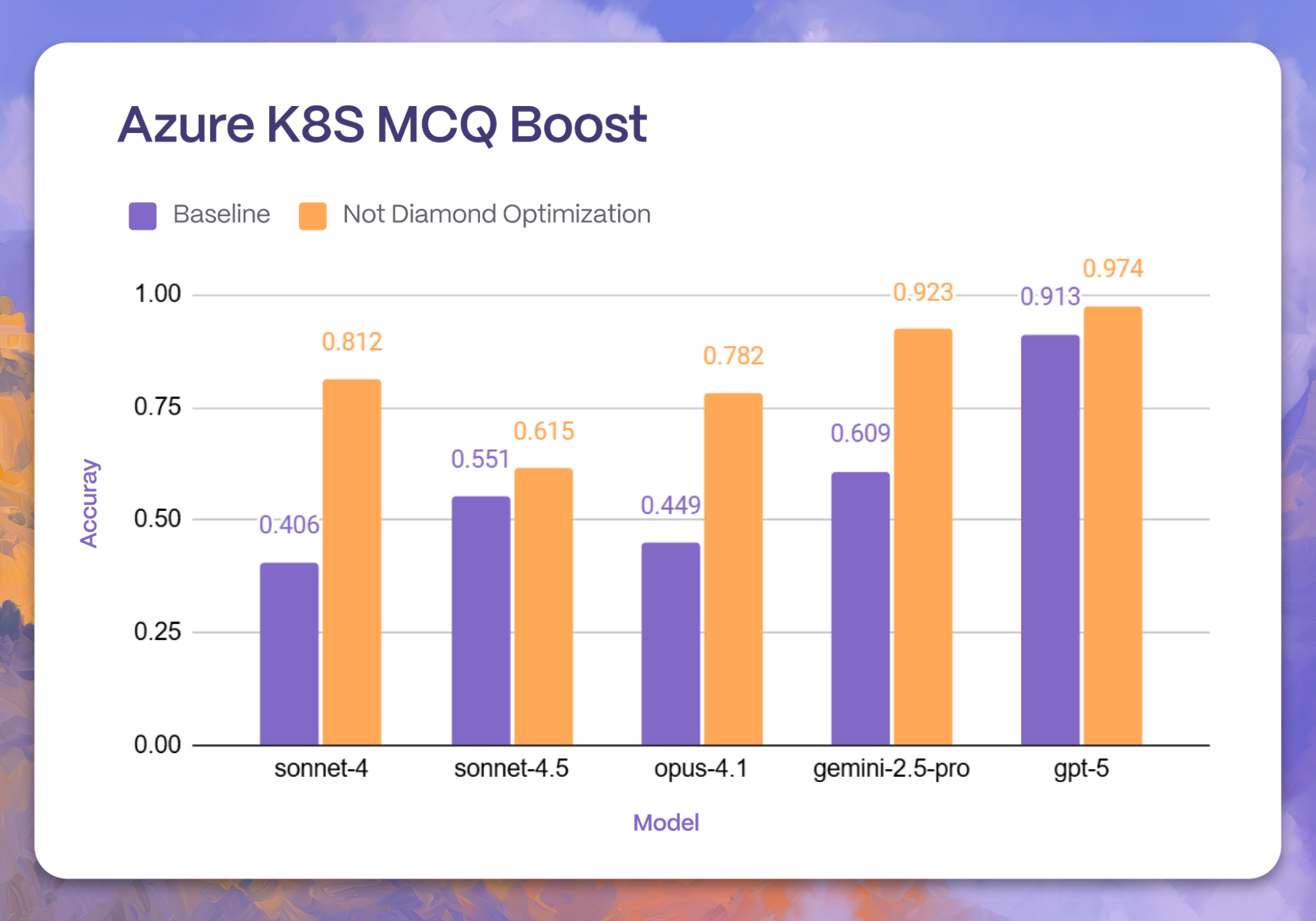
We immediately notice that Prompt Adaptation generalizes pretty strongly across all environments. For instance, Prompt Adaptation boosted all five models to attain comparable performance on code understanding with GMCQ.
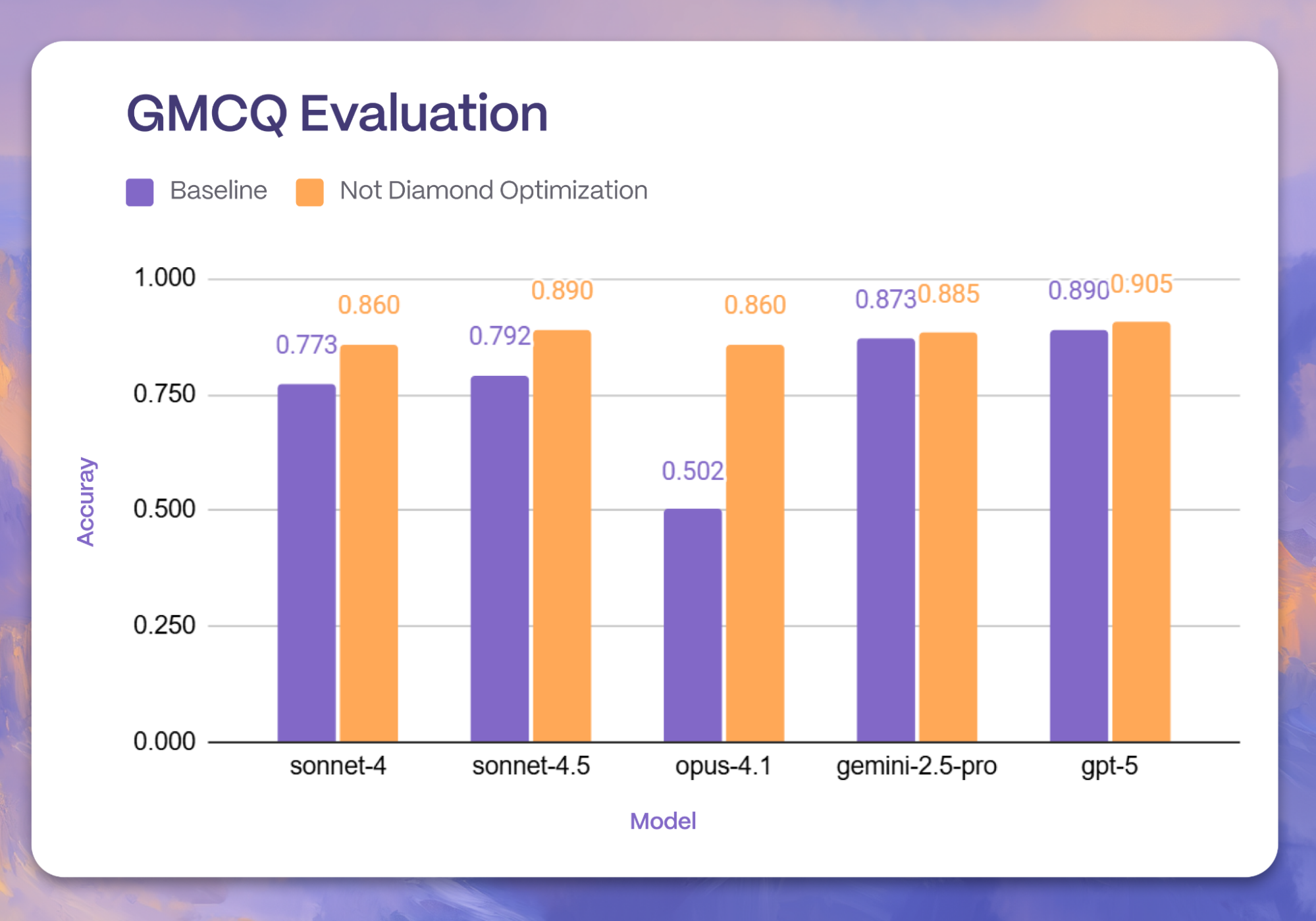
Prompt Adaptation continues to show even more impressive gains on the Terraform Azure K8S task, with improvements up to 2x improved accuracy on this SRE benchmark. Comparable improvements are also visible in the Terraform S3 Security task to benchmark model understanding of SRE tasks, further demonstrating cases of noticeable boosted model performance.

The adapted prompts delivered significant gains across most configurations (12 out of 15), with an average relative lift of 39% (or 31.22% across all 15 runs) and maximum of 102.77%.
The improvements we observed show that prompt adaptation doesn’t just refine model behavior; it expands what these systems are capable of. It also reinforces the value of a multi-model future, where optimized prompts reveal that different models perform best in different scenarios. For anyone building AI applications, it underscores a simple truth: the next leap in performance will come not only from better models but from better ways of prompting and combining them.
Test it out and contribute
If you want to use Rootly’s EFCB benchmark, feel free to download it via ourout GitHub page, we also partnered with Groq to have it available in OpenBench, an open-source evaluation infrastructure for language models providing standardized, reproducible benchmarking for LLMs across 30+ evaluation suites. It only takes one command to run EFCB with OpenBench!
If you are interested in contributing to the project, please get in touch. The Rootly AI Labs is a fellow-led community developing innovative open-source prototypes, tools, and research. We build in public and share everything on our GitHub page.
Lastly, thank you to Anthropic, Google Cloud, and Google DeepMind for their support of the Labs.





