

.avif)

































Rootly joins Groq OpenBench with an SRE-focused benchmark
Making LLM evaluations reproducible for real-world SRE workflows


Don't let an incident catch you off guard - download our new Incident Comms Playbook for effective incident comms strategies!
By submitting this form, you agree to the Privacy Policy and Terms of Use and agree to sharing your information with Rootly and Google.
July 4, 2025
6 mins
Run better post-mortem meetings. Our guide covers when a post-mortem is truly needed based on severity, a 6-step process to find root causes, and free templates to turn learnings into action.

.png)

This guide shows you how to run post-mortem meetings that actually work. Learn when a formal post-mortem is necessary (and when it isn't), follow a 6-step process to find the real root cause, and use proven templates to ensure your learnings turn into concrete action items.
A post-mortem meeting is a structured, blameless discussion held after an incident, outage, or project completion to analyze what happened and why. The goal is to create a shared understanding of the event and produce concrete, actionable steps to prevent repeat failures and improve future performance. It’s a foundational process for any team focused on learning from both their successes and failures.

A well-run post-mortem is more than just a recap—it’s a powerful tool for continuous improvement. One of the biggest benefits is improved team communication; when everyone has a chance to share their perspective in a safe environment, it increases transparency and builds trust. By focusing on learning, your team can develop actionable plans that lead to more reliable systems, a more effective engineering process, and ultimately, better outcomes.
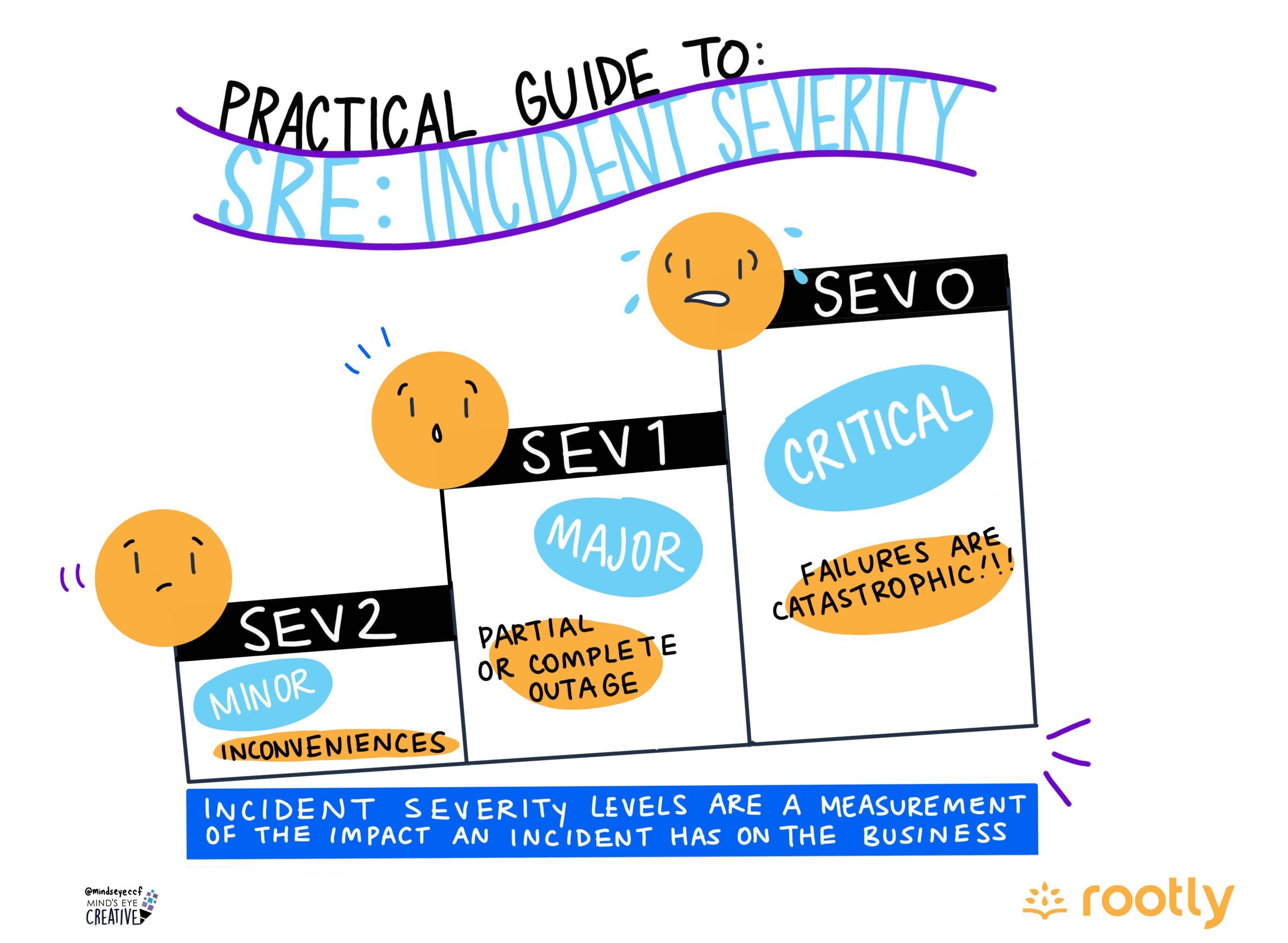
Not all incidents are created equal, and your response shouldn’t be either. A minor hiccup doesn’t require the same deep-dive analysis as a site-wide outage. The key is to match the effort of the review to the severity of the impact.
Here’s a practical guide to deciding if—and how—you should conduct a post-mortem.
SEV-0 / SEV-1: Critical & Major Incidents(e.g., Site-wide outage, major data corruption, SLA breach)
Verdict: Yes, always. A full, formal post-mortem is non-negotiable.These are your most expensive and painful incidents and, therefore, your most valuable learning opportunities. A rigorous review is mandatory for internal learning and for maintaining customer trust.
SEV-2 / SEV-3: Minor & Low-Impact Incidents(e.g., A transient error spike, a failed deployment that was instantly rolled back)
Verdict: Usually not. Focus on lightweight, automated tracking.Forcing a formal meeting for every minor issue leads to “post-mortem fatigue.” The goal here isn’t a deep investigation but signal detection. Are these minor incidents happening frequently?
A well-facilitated meeting follows a clear structure. Preparing talking points in advance helps guide the discussion and keeps the meeting focused on the most important topics.
1. Set the Stage
Your first job as a facilitator is to break the tension. Acknowledge the stress of the incident, thank the team for their work, and immediately state the ground rule: “We’re here to understand our system’s weaknesses, not to find someone to blame.” Appoint your dedicated notetaker, and ensure everyone has access to the agenda and any preliminary reports.
How Rootly Helps: You can skip the painful scramble for context. Rootly pieces together the entire story for you—every alert, Slack message, and timeline event—into a clean brief you can send out beforehand.
2. Walk Through the Timeline
Your goal is to create a shared, factual understanding of the sequence of events. Have the Incident Commander or a key responder narrate a concise timeline, covering detection, escalation, key mitigation actions, and final resolution.
How Rootly Helps: This step is drastically simplified with an incident management platform. Rootly's AI automatically generates a detailed timeline, turning hours of manual work into a one-click action.
3. Identify What Went Well
Before you jump into what broke, take five minutes to talk about what didn’t. Was an alert particularly helpful? Did a runbook save the day? Acknowledging what worked isn’t just for morale; it’s how you identify and reinforce reliable processes. Then, ask the most important question: “Where did we get lucky?” Uncovering where you almost had a much bigger disaster is pure gold for preventing future incidents.
4. Analyze Failures and Gaps
This is the core of the meeting. Guide the team through a root cause analysis using targeted questions to uncover underlying issues. The “5 Whys” technique is a simple but powerful tool to move past symptoms to systemic causes. Remember to keep the focus on process gaps, tooling blind spots, or areas of unclear ownership—not on individual blame.
How Rootly Helps: Rootly’s AI surfaces root-cause insights by analyzing incident data and suggesting contributing factors, helping your team get to the heart of the matter faster.
5. Define Action Items
This is where most post-mortems fall apart. Don’t end with a vague list of “things we should do.” For every issue, create a concrete task and assign it to a single person. Ask them directly: “Can you get this done, or do we need to make it a bigger project for the next sprint?” This public commitment turns a fuzzy idea into accountable work.
How Rootly Helps: Capture action items directly within Slack. Rootly’s native integration with Jira, Linear, and ServiceNow allows you to create and assign tickets instantly, ensuring nothing gets lost.
6: Finalize the Notes and Spread the Knowledge
The work isn’t done until the lessons are shared. Distill the raw notes from the meeting into a clean, easily digestible report. The goal is to ensure the pain of this incident benefits the entire organization, so actively push key learnings out. Pull out the finding about the monitoring gap and send it to the observability team. Share notes on a confusing workflow with the right product manager.
How Rootly Helps: Rootly builds the report in the background, automatically assembling the timeline, participants, and action items. Finalizing the report becomes a 10-minute task of cleaning up notes, not a multi-hour writing assignment.

.png)
Get more features at half the cost of legacy tools.



Get more features at half the cost of legacy tools.

.jpg)

Get more features at half the cost of legacy tools.

Get more features at half the cost of legacy tools.

.jpg)


Get more features at half the cost of legacy tools.




