

.avif)





















Streamlined Incident Post‑Mortems: A Concise Template + AI prompts for artefacts
Turn oops into aha


Don't let an incident catch you off guard - download our new Incident Comms Playbook for effective incident comms strategies!
By submitting this form, you agree to the Privacy Policy and Terms of Use and agree to sharing your information with Rootly and Google.
November 5, 2021
8 min read
Explore the roles of SLIs, SLOs, and SLAs in site reliability engineering and how they empower your team to plan, prioritize, and perform with confidence.

TL;DR: Last updated: July 17th, 2025
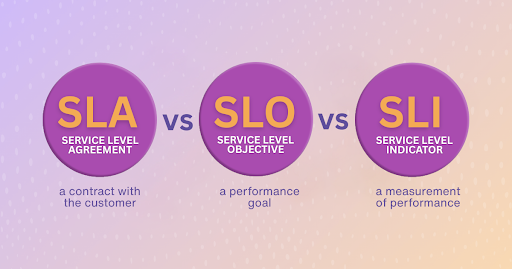
This guide has been updated to provide the clearest, most current explanation of SLAs, SLOs, and SLIs. Here’s the gist:
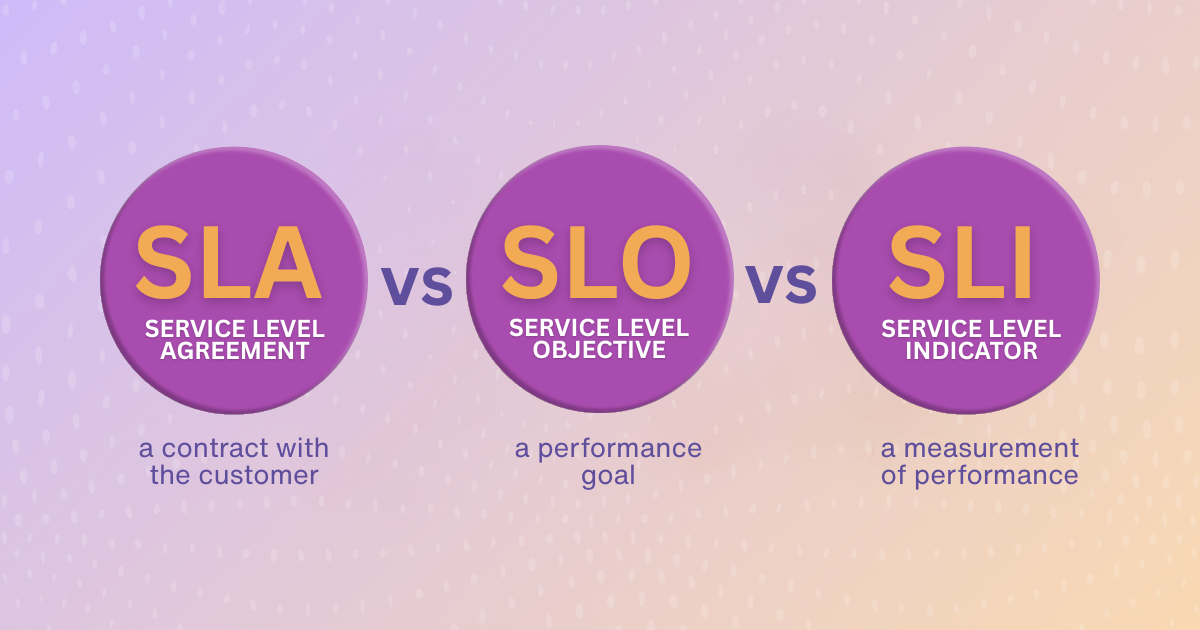
SLAs, SLOs, and SLIs form the foundation of modern site reliability engineering (SRE). They influence how incidents are tracked, how engineering teams prioritize efforts, and how businesses maintain customer trust. Yet, too often, these terms are lumped together without clarity or used interchangeably. This guide aims to clean up the confusion.
We’ll walk through each term—starting with SLIs as the building blocks, SLOs as the internal north stars, and SLAs as the external commitments. Along the way, we’ll touch on common challenges, real-world examples, and strategies for getting these right.

An SLI is a data-driven measurement of system behavior. It quantifies how your service is performing from the user’s point of view—things like availability, latency, error rates, and system throughput.
The hardest part of working with SLIs is not the math—it’s the relevance. Choosing an SLI that doesn’t reflect the customer experience can lead teams to optimize the wrong things. Worse, if the data pipeline is unreliable or poorly defined, decisions made from those SLIs can derail service improvement.
SLIs are used by SREs, DevOps engineers, QA teams, and anyone responsible for uptime and reliability. They feed alerting systems, support capacity planning, and inform incident reviews.

An SLO is a clearly defined performance target based on SLIs. It’s a statement of intent: "We aim to achieve 99.9% availability of our login service over the past 30 days."
Teams often struggle to set achievable SLOs. Set them too low, and they’re meaningless. Set them too high, and they set you up for alert fatigue or frequent failure. There’s also the challenge of making sure product and engineering agree on what "good enough" means.
Product managers, SREs, and engineering leaders rely on SLOs to prioritize reliability without slowing down progress. They become the baseline for error budgets—how much unreliability is acceptable within a given period.
SLOs create accountability, but error budgets allow flexibility. An error budget lets your team innovate and deploy changes as long as the budget isn't burned. Once it is, it's a signal to pause and focus on stability.
Start with historical data—what’s your system currently capable of? Then, bring product and engineering together to define what reliability means. Revisit regularly as your system and customer expectations evolve.

An SLA is a legal document or contract between a service provider and a customer. It defines what level of service is guaranteed, and what penalties apply if those promises aren’t met.
The stakes are higher here. Overpromising in an SLA can cost your company—financially, reputationally, or both. And if the metrics aren’t grounded in reliable data (SLIs) and reasonable targets (SLOs), you’re flying blind.
SaaS vendors, cloud infrastructure providers, managed service providers—anyone delivering digital services under contract. Clients rely on SLAs to ensure accountability and performance.
Think of SLAs as promises to the outside world. SLOs are promises to yourself. SLAs carry consequences. SLOs drive alignment. They must inform one another, but they are not the same.
Start with what your system can realistically deliver. Include exceptions (e.g., scheduled maintenance), remedies (credits or refunds), and response timelines. Most importantly, don’t treat SLAs as static—review them as your service evolves.
Understanding how SLAs, SLOs, and SLIs differ isn’t just helpful—it’s essential for building resilient systems. The table below simplifies their distinctions, so you can make confident, data-driven decisions in your reliability strategy.
While the distinctions in the table are clear-cut, what truly matters is how your team interprets and applies them. SLAs, SLOs, and SLIs aren’t just policy terms—they’re living agreements between your system, your teams, and your users.
When these three align, you not only gain technical clarity but also empower your team to prioritize the work that matters most. Reliability becomes a shared responsibility, not just an SRE concern.
Reliability doesn’t exist in a vacuum. SLAs, SLOs, and SLIs give everyone—from engineers to executives—a shared language to measure success. This alignment ensures that technical metrics translate into real business impact.
Whether you're a platform team managing microservices or a SaaS company supporting customers, these frameworks create transparency. They help define who owns what, when action is required, and what success looks like. As a result, teams can operate with greater autonomy and clarity.
SLOs define what good looks like. They help filter out unnecessary noise from alerting systems and keep engineers focused on meaningful incidents. This focus ultimately reduces burnout and supports sustainable on-call practices.
SLAs aren’t just paperwork—they’re promises. When honored, they build long-term loyalty and reinforce credibility. And when breached, they offer a structured path to make things right and maintain the customer relationship.

.png)
Get more features at half the cost of legacy tools.



Get more features at half the cost of legacy tools.

.jpg)

Get more features at half the cost of legacy tools.

Get more features at half the cost of legacy tools.

.jpg)


Get more features at half the cost of legacy tools.




