When something breaks, people look to the person who can cut through noise, decide, and align the team. If you run a platform, clinic, facility, or public service, put an Incident Commander in place before the first alert as part of a formal incident response program. The Incident Commander leads the incident response team, establishes clear accountability, and drives a workable plan that keeps the response moving without collisions.
With an Incident Commander, updates are predictable, priorities are sequenced, and risk is surfaced early. Teams act once, not twice. Customers get faster recovery and credible communication. Afterward, the same leader ensures complete documentation for the post mortem, turns findings into actions, and strengthens the incident response process so the next event is easier to manage. The practical steps are simple to adopt and pay off when it counts.
Key Takeaways:
Name one incident commander early and publish who it is with clear activation criteria.
Give the incident commander a tight action plan with measurable objectives, owners and backups, time boxes, risks, and exit checks.
Keep communications on a clock as the incident commander uses templates, separates channels, shares facts, and maintains a live timeline.
Track outcomes the incident commander influences: time to acknowledge, engage, mitigate, resolve by severity percentiles, plus customer impact and update adherence.
Afterward, the incident commander leads a blameless review, selects three to five high value fixes, assigns owners and dates, updates playbooks, and drives drills.
What Is an Incident Commander
An Incident Commander is the single accountable leader who directs the response to a disruption, outage, breach, or safety event. The role exists in technology, cybersecurity, healthcare, utilities, manufacturing, and public safety. The Incident Commander sets objectives, aligns teams, and ensures a safe and timely return to normal operations.
Core objectives and success criteria
Your objectives are simple and measurable:
Protect people and assets
Minimize customer impact and business loss
Restore service within agreed timelines
Communicate clearly to all stakeholders
Capture evidence and learning for improvement
Success criteria include fast acknowledgment, rapid mitigation, consistent updates, reduced customer minutes of impact, and action items completed after the event.
When to designate an Incident Commander?
Designate an Incident Commander when an event meets predefined severity thresholds, affects multiple teams, risks safety or compliance, or requires cross functional coordination. If there is confusion about who leads, you already need one.
Single vs Unified Command overview
Single Command is used when one organization or function owns the response. Unified Command is used when multiple agencies or companies must collaborate. In Unified Command, leaders agree on shared objectives, assign a single spokesperson, and publish one plan and one cadence of updates.
Where the Incident Commander Fits in the Incident Command System
Command structure and key relationships
The Incident Command System is a standard way to organize an incident response team. The Incident Commander leads with clear objectives, safety guardrails, and one path for decisions and updates.
Command staff vs general staff
Command staff
Safety Officer: monitors risk and can halt unsafe work
Communications Lead: drafts and publishes updates
Liaison Officer: coordinates with executives, partners, and agencies
General staff
Operations: runs tactics to meet objectives
Planning: maintains the plan, timeline, and status
Logistics: provides people, access, tools, and facilities
Finance or Administration: tracks cost, contracts, and compliance
Role boundaries and handoffs
Incident Commander: sets objectives, approves the plan and updates, decides on escalation and closure
Operations: executes work and reports progress
Planning: turns objectives into a time boxed plan and captures decisions and evidence
Logistics: secures resources and manages rotations
Finance or Administration: records spend and regulatory actions Keep the Incident Commander separate from the Technical Lead to prevent role collisions.
Transfer of command protocols
When: a more qualified leader arrives, severity changes, shift change, or fatigue threatens judgment
How: brief, accept, announce, record
Outgoing briefs objectives, impact, risks, active tactics, resources, next update time
Incoming accepts responsibility and notes immediate changes
Communications announces the new Incident Commander and next update time
Scribe records time, names, reason, and any adjustments
Delegation of authority and span of control
Delegate routine approvals to Operations and Planning
Retain decisions on objectives, external communications, severity changes, and closure
Keep span of control to about five to seven direct assignees, name deputies for long events, and pre approve fast paths such as safe, reversible rollbacks
Core Responsibilities of the Incident Commander
Set incident objectives and strategy - Translate impact into a small set of measurable outcomes. Use a simple formula: verb, metric, scope, time bound, success signal.
Establish and maintain a clear command structure - Name the Incident Commander, Operations, Planning, Logistics, Finance or Administration, Communications, Safety, and a scribe. Publish who approves objectives, plan changes, resource moves, and external messages. Assign deputies for events expected to exceed one operational period.
Build the Incident Action Plan - Keep it short, current, and visible. Refresh at each operational period.
Objectives - Outcome based and prioritized. Tie each to a verification signal and owner.
Operational periods - Choose a period length that matches severity. For major incidents use 30 to 60 minutes. Start each period with a five minute standup and end with a brief review.
Resources and assignments - List owners, backups, required access, and the single source of truth for work items. Prevent dual hatting of the Incident Commander and Technical Lead.
Safety and constraints- Record change freezes, data handling rules, access limits, and any physical safety requirements. Note approved rollback paths.
Maintain safety as the first priority - Stop or defer tactics that introduce unacceptable risk to people, data, or critical systems. Ask the Safety Officer for a go or no go when risk is unclear.
Lead decision making and prioritization - Frame options, expected effects, risks, and rollback. Choose the highest value action with the shortest safe time to impact. Record the decision, owner, and timer to verify result.
Coordinate communications and stakeholder updates - Set a clock for updates and keep it. Approve content for internal channels, customer status pages, and executive briefs. State what happened, who is affected, what is being done, and when the next update will arrive.
Approve resource requests and allocations - Move people and tools to the highest leverage objectives. Escalate access blocks and vendor engagement early. Rotate responders to protect decision quality.
Manage risk and legal or regulatory exposure - Engage Safety, Legal, and Compliance when data, privacy, or reporting thresholds may be met. Preserve logs, tickets, screenshots, and chat exports. Avoid speculation and keep statements factual.
Ensure documentation and timeline capture - Require a live timeline with timestamp, actor, action, expected effect, observed result, and link to evidence. This becomes the source for the post incident review and customer facing summaries.
Decide on escalation or de escalation paths - Change severity based on customer impact, data exposure, regulatory implications, and trajectory. Publish the reason for the change and the new cadence of updates.
Authorize resolution, recovery, and closure - Confirm exit criteria before declaring resolved. Typical criteria include stable metrics for one or two operational periods, cleared backlogs, no active customer reports, and monitoring alerts within normal ranges. Assign owners and due dates for recovery tasks, customer follow ups, and preventive actions. Announce closure with a summary and the timeline for the post incident review.
Skills and Leadership Traits of Effective Incident Commanders
Communication clarity and brevity: Use short, plain language. Replace jargon with observable facts and numbers.
Situational awareness and systems thinking: Track dependencies, leading indicators, and potential secondary failures.
Decisiveness under uncertainty: Choose a viable path with the information available. Time box the decision and adjust as new data emerges.
Calm presence and psychological safety: Model steady behavior so others can think clearly. Invite dissenting data and alternative hypotheses.
Negotiation and conflict resolution: Resolve priority disputes by restating objectives and tradeoffs. Seek workable agreements quickly.
Technical fluency without overreach: Understand enough to ask sharp questions and translate signals to decisions. Avoid doing hands on work yourself.
Ethical judgment and accountability: Own outcomes, protect customers and staff, and escalate when pressure conflicts with safety.
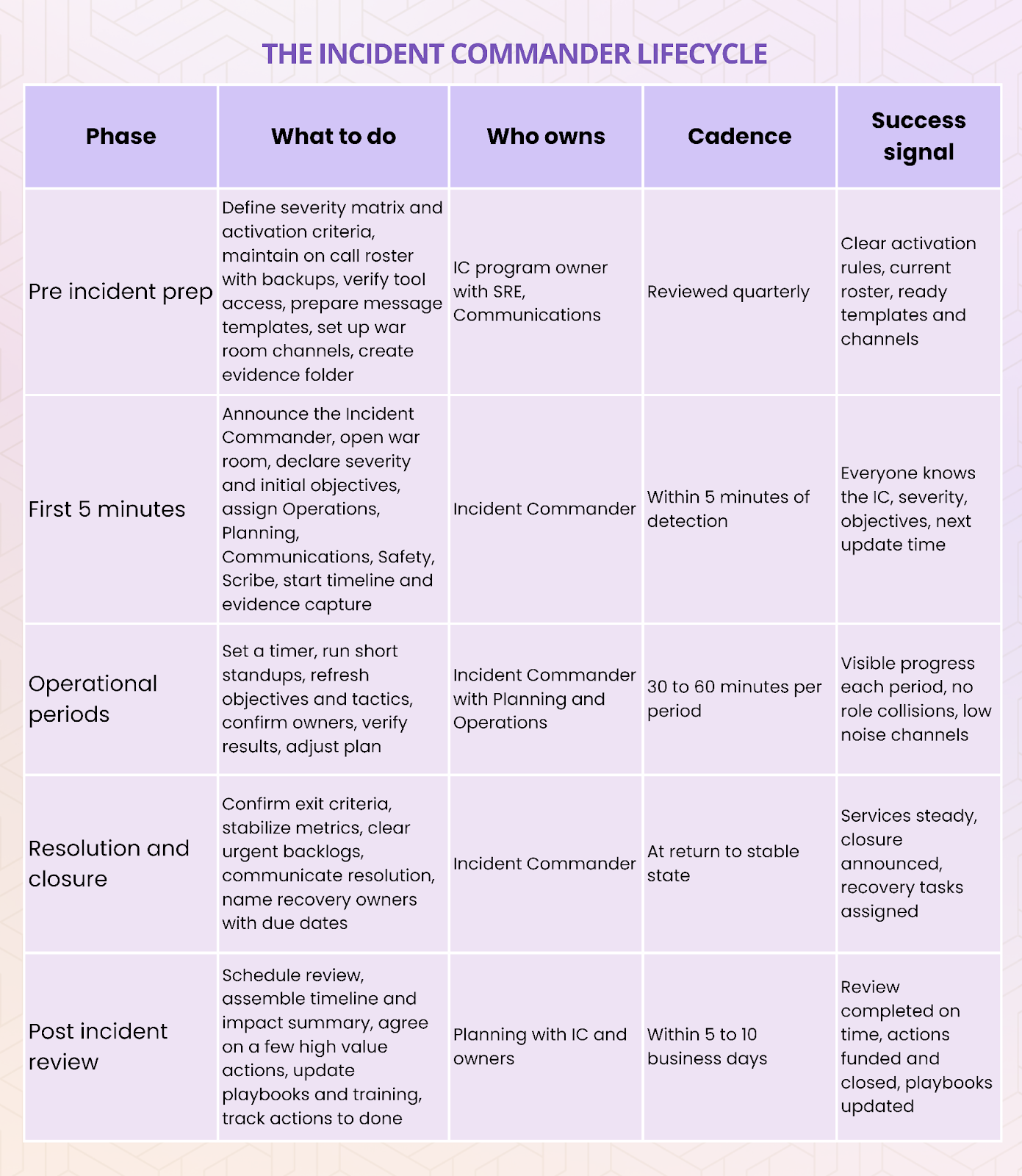
The Incident Commander Lifecycle
Pre incident preparation
Readiness checklist
Severity matrix and clear activation criteria with examples
On call roster with backups and an escalation tree
Contact lists and distribution groups for responders, leaders, customers, and regulators
Access to dashboards, runbooks, ticketing, and the status page
Pre approved message templates for acknowledgment, progress, and resolution
War room channels and conference bridges that are tested and documented
Evidence capture location with naming standards and permissions set
Tabletop drill schedule and success measures for detection, mobilization, and decision quality
Team roster and on call rotation
Maintain a fair rotation with primary and deputy Incident Commanders. Publish response time expectations, handoff rules, and how to reach executives after hours.
Playbooks and runbooks
Keep living documents with decision trees, rollback procedures, failure mode checks, and verification steps. Link each playbook to owners and a review cadence.
Tool access and permissions
Audit access quarterly and after org or vendor changes. Test sign in paths, status page publish rights, ticket queues, observability dashboards, and vendor support channels.
During the incident
First five minutes checklist
Assume command and announce the IC
Open the war room and invite roles
Declare severity and initial objectives
Assign Operations, Planning, and Communications leads
Start the live timeline and evidence capture
Establishing channels and roles
Create a command channel, an operations channel, and a customer updates channel. Keep them separate to reduce noise.
Setting objectives and operational periods
Set a timer. At each period end, review progress, adjust objectives, and document decisions.
Information triage and verification
Require two point confirmation for key facts. Mark hypotheses versus confirmed statements.
Decision logs and action confirmation
Log decisions with time, owner, and expected result. Confirm actions completed.
Post incident follow through
Structured handoff to recovery owners - Name owners for backlog work, data repair, and customer follow ups.
Lessons captured and disseminated - Publish a digestible summary to all affected teams and leaders.
Communications Playbook for the Incident Commander
Internal communications cadence
Channel setup and norms
Create channels with clear names such as incident command, incident operations, and incident updates. Require thread discipline and action tags such as owner, due time, and status.
Update intervals by severity level
Sev 1: every 15 to 30 minutes
Sev 2: every 30 to 60 minutes
Sev 3: every 60 to 120 minutes
External communications patterns
Customer status pages and notifications
Post initial acknowledgment quickly with what you know, who is affected, and next update time. Mirror to email or in app notices if needed.
Regulator or partner notifications
Use pre approved language. Capture the exact time and delivery method.
Message templates
Initial acknowledgement
“We are investigating an incident affecting checkout latency for a subset of users. Mitigation is in progress. Next update within 30 minutes.”
Progress updates
“Mitigation reduced error rate from 12 percent to 3 percent. Root cause under investigation. Next update at 14 30 UTC.”
Resolution and follow up
“The incident has been resolved. Services are stable and monitored. A post incident review will be published within 5 business days.”
Meeting rituals
Standups and huddles
Run five minute standups at the start of each operational period. Confirm owners, blockers, and decisions.
Decision reviews and checkpoints
Hold short checkpoints with executives when risk or customer impact changes significantly.
Tooling and Data for Command and Control
Effective command and control runs on a small, reliable stack. Use a persistent chat channel, a standing video bridge, and a virtual whiteboard. Record who attended and what was decided. Ensure paging and ticketing route alerts to the correct on call roles and track work in a shared queue with clear owners and due times.
Let telemetry guide the response through dashboards for latency, error rates, saturation, and user reports. Avoid chasing anecdotes without data. Publish updates through a status page and stakeholder portals, automating where possible and tailoring messages to each audience. For evidence, create a folder for every incident that stores the timeline, logs, screenshots, and copies of communications.
Building the Incident Action Plan in Practice
Turn objectives into concrete tactics that deliver fast, safe impact. If the goal is to restore service within 45 minutes, select the highest probability, lowest risk options first such as rollback, disabling a feature flag, traffic shaping, or failover. Give each tactic a single owner and a named backup, set a firm time box, and define how success will be verified before you begin.
Document risks and constraints up front, including potential blast radius, data change risks, and the exact rollback path. Plan surge capacity for long incidents by bringing in extra responders early and rotating roles to prevent fatigue. Set clear exit criteria for each operational period, for example error rate under 1 percent for 15 minutes, queues back to baseline, or customer complaints trending down.
Decision Making Under Pressure
Use simple frameworks to keep choices clear. Apply the OODA loop to observe metrics and context, orient to objectives, decide on a tactic, act, and verify results. Prepare a PACE plan so primary, alternate, contingency, and emergency options are ready before execution. Build a course of action table that lists each option with expected effect, time to impact, risk, and rollback path, then select the highest expected value.
When signals conflict, label unknowns, run small reversible tests, and increase sampling or logging to cut uncertainty. Pause operations if any step risks injury, irreversible data loss, or non compliant exposure. Ask the Safety Officer to review the plan and confirm safeguards before resuming.
Best Practices for High Performance Incident Command
Practice with realistic simulations and game days
Run surprise drills with real constraints such as missing access, noisy alerts, and vendor delays. Time each step from detection to mitigation, score decision quality, and capture gaps for action.
Rotate and shadow to reduce single points of failure
Build a bench of deputy Incident Commanders. Use shadowing and short co leading assignments, then graduate deputies to lead low severity events before major ones.
Use pre approved templates and checklists
Standardize acknowledgment, progress, and resolution messages. Keep a short first five minutes checklist and a transfer of command script so responders move fast with consistent language.
Maintain a living playbook and glossary
Assign owners, add a change log, and review after every incident. Include definitions for roles, severity, and channels so new responders understand the system quickly.
Measure and improve with actionable metrics
Tie metrics to objectives such as time to acknowledge, time to mitigate, update cadence adherence, evidence completeness, and action completion rate. Review results in leadership forums and fund the fixes that reduce the most risk.
Common Pitfalls and How to Avoid Them
Confusion over who leads slows everything. Name a single Incident Commander and publish it in every channel. Resist co leadership. Another trap is getting pulled into hands on troubleshooting. The Incident Commander should ask sharp questions, set priorities, and make decisions, not type commands. Scope creep appears when teams chase interesting work. Re read objectives at each operational period and cut tasks that do not move those goals.
Communication failures cause either silence or noise. Set a clear update cadence and stick to it. Share verified facts, actions in flight, and the next update time. Documentation gaps hurt post incident learning. Keep a scribe and save logs and evidence continuously. Fatigue erodes judgment in long events. Rotate roles, enforce breaks, and use deputies to keep decision quality high.
Post Incident Review Led by the Incident Commander
Blameless analysis principles
Examine how the system produced the outcome, not who to blame.
Use a fact based timeline and direct quotes from the war room, tickets, and logs.
Call out decision points and the information available at the time to avoid hindsight bias.
Identify contributing factors across detection, mobilization, diagnosis, mitigation, recovery, and communications.
Capture what worked well so strengths become standard practice.
Selecting focus areas and prioritizing actions
Group findings into themes such as alert quality, access and permissions, playbooks, resilience, and stakeholder updates.
Choose a small set of actions that remove the most risk per unit of effort.
Use a simple score that multiplies expected risk reduction by customer impact, then divides by effort.
Limit to three to five top actions, each with a clear owner, due date, and success signal.
Writing an executive summary that informs investment
Create a one page brief leaders can read in two minutes:
Impact: who was affected, duration, severity, customer impact minutes, error budget burned
Timeline: key events from detection to resolution with times
Contributing factors: the few that mattered most
What worked: practices that sped detection or recovery
Decisions: high leverage choices and their rationale
Recommendations: funded actions and larger investments with expected risk reduction
Tracking and verifying action items to completion
Open a ticket for each action and link it to the incident record.
Define verification steps before work starts, such as drill results or metric targets.
Review status in a weekly forum until all actions are complete.
After deployment, validate effectiveness through a drill or the next similar event, then update playbooks, templates, and training.
Strong incident command rests on clear leadership, observable objectives, disciplined communication, and continuous learning. Put the structure in place before the alarm, rehearse often, and measure what matters. Protect safety, make timely decisions, and document the truth. Do this consistently and every incident becomes a chance to strengthen systems and trust. At Rootly, we help incident commanders lead faster by automating setup, guiding response with AI, and turning every incident into measurable, repeatable improvement.
AI-Powered On-Call and Incident Response
Get more features at half the cost of legacy tools.


.avif)





























.png)




.jpg)



.jpg)







